








The success of foundation models such as BERT, GPT-3, CLIP, and Codex has generated increased interest in models that combine vision and language modalities. These hybrid vision-language models have demonstrated impressive capabilities in challenging tasks, including image captioning, image generation, and visual question answering. A new paradigm of video foundation models that learn from video data using the principles of foundation models has recently emerged.
This blog post provides an overview of foundation models, large language and vision-language models, and video foundation models. We explore the architecture of foundation models, their training and fine-tuning paradigm, and the scaling laws. Additionally, we discuss how vision-language models combine the power of computer vision and natural language processing and how they are being used to solve complex problems. Finally, we examine video foundation models and how they are revolutionizing the understanding and analysis of video data.
1 - A Gentle Intro to Foundation Models
A foundation model is a type of machine learning model that learns from a wide range of data using self-supervision at scale. The idea is to create a model that can be used for many different tasks. By training on lots of data, the model can learn the general patterns in the data. When the model is used for a specific task, it can use this knowledge to quickly adapt.
Foundation models use deep neural networks, which have been popular since 2012, and self-supervised learning, which has been around for almost as long. Recent improvements in both areas have allowed for the creation of larger and more complex models. These models are trained on massive amounts of data, often without explicit labels.
The result is a model that can learn a wide range of patterns and relationships, which can be used for many tasks. This has led to significant improvements in natural language processing, computer vision, and multimodal AI. With foundation models, we can create one model that can be used for many tasks, rather than creating different models for each task. This can save time and resources and speed up progress in many fields.
Transfer Learning
Traditional machine learning (ML) models are trained from scratch (if not almost) and require lots of domain-specific datasets to perform well. However, if you only have a small amount of data, you can leverage the benefit of transfer learning. The idea of transfer learning is to take the "knowledge" learned from one task and apply it to another task so that you don’t require as much data as you would if you were to train from scratch. For deep neural networks, pre-training is the dominant approach to transfer learning: you train the model on an original task (i.e, detecting cars on the street) and fine-tune it to another downstream task of interest (i.e, detecting a black Tesla Model 3).
We have been doing this in computer vision since 2014. Usually, you train a model on ImageNet, keep most of the layers, and replace the top three or so layers with newly learned weights. Alternatively, you can fine-tune the model end-to-end. Some of the most popular pre-trained models for computer vision tasks include AlexNet, ResNet, MobileNet, Inception, EfficientNet, and YOLO.
In natural language processing (NLP), pre-training was initially limited only to the first step: word embeddings. The input to a language model is words. One way to encode them as a vector (instead of a word) is through one-hot encoding. Given a large matrix of words, you can create an embedding matrix and embed each word into a real-valued vector space. This new matrix is reduced to the dimension on the order of a thousand magnitude. Perhaps those dimensions correspond to some semantic notion.

Word2Vec trained a model like this in 2013. It looked at which words frequently co-occur together. The learning objective was to maximize cosine similarity between their embeddings. It could perform cool demos of vector math on these embeddings. For example, when you embed the words "king," "man," and "woman," you can do vector math to get a vector that is close to the word "queen" in this embedding space.
It's useful to see more context to correctly embed words because words can play different roles in a sentence depending on their context. If you do this, you'll improve accuracy on all downstream tasks. In 2018, several models, including ELMo, ULMFiT, and GPT, have empirically demonstrated how language modeling can be used for pre-training. All three methods employed pre-trained language models to achieve state-of-the-art results on a diverse range of tasks in NLP, including text classification, question answering, natural language inference, coreference resolution, sequence labeling, and many others.
Transformers = The Underlying Architecture For Foundation Models
The original version of Transformers was introduced in a 2017 paper called "Attention Is All You Need". Prior to Transformers, the state of the art in NLP was based on recurrent neural networks (RNNs), such as LSTMs and the widely-used Seq2Seq architecture, which processed data sequentially – one word at a time, in the order that the words appeared.
Transformers' innovation is parallelizing language processing. This allows all the tokens in a given body of text to be analyzed simultaneously, rather than in sequence. Transformers rely on an AI mechanism known as attention to support this parallelization. Attention enables a model to consider the relationships between words, even if they are far apart in a text, and to determine which words and phrases in a passage are most important to pay attention to.
Parallelization also makes transformers much more computationally efficient than RNNs, allowing them to be trained on larger datasets and built with more parameters. Today's transformer models are characterized by their massive size.
Vision Transformers
Convolutional Neural Networks have been the dominant architecture in the field of computer vision. However, given the success of Transformers in NLP, researchers have started adapting this architecture to image data. The paper "An Image is Worth 16 x 16 Words: Transformers For Image Recognition at Scale" introduces the Vision Transformer (ViT) architecture, which applies the encoder block of the Transformer architecture to the image classification problem.
The author of this work split an image into patches and provided the sequence of linear embeddings of these patches as input to a Transformer. Similar to tokens in the NLP setting, these image patches are treated as inputs. The architecture includes a stem that patches images, a body based on the Multi-Layer Transformer encoder, and a Multi-Layer Perceptron (MLP) head that transforms the global representation into the output label. The ViT sets or exceeds state-of-the-art results on many image classification datasets while being relatively inexpensive to pre-train.
Although ViTs show potential, they have some problems. One significant issue is that they have difficulty with high-resolution images because they require a lot of computing power, which increases rapidly with image size. Additionally, the fixed-scale tokens in ViTs are not useful for tasks that involve visual elements of varying sizes.
Transformer Variants
A flurry of research work followed the original Transformer architecture, and most of them made enhancements to the standard Transformer architecture in order to address the above-mentioned shortcomings.
In 2021, Microsoft researchers published the Swin Transformer, a generic Transformer architecture that can be applied to any modality. The Swin Transformer introduced two concepts: hierarchical feature maps and shifted window attention.
1. The model uses hierarchical feature maps to enable advanced techniques for dense prediction. It achieves linear computational complexity by computing self-attention locally within non-overlapping windows that partition an image. This makes Swin Transformer a good backbone for various vision tasks.
2. The use of shifted windows enhances modeling power by bridging windows of the preceding layer. The strategy is also efficient in terms of real-world latency: all query patches within a window share the same key set, making memory access in hardware easier.
Perceiver is another Transformer variant created by DeepMind around the same time that takes inspiration from biological systems. It uses attention-based principles to process various types of input, including images, videos, audio, and point clouds. It can also handle combinations of multiple types of input without relying on specific assumptions about the domain.

The Perceiver architecture introduces a small set of latent units that forms an attention bottleneck. This eliminates the problem of all-to-all attention and allows for very deep models. It attends to the most relevant inputs, informed by previous steps. However, in multimodal contexts, it is important to distinguish input from one modality or another. To compensate for the lack of explicit structures, the authors associate position and modality-specific features with every input element, similar to the labeled line strategy used in biological neural networks.
2 - Large Language Models
Following the original Transformer paper, a flurry of innovation occurred as leading AI researchers built upon this foundational breakthrough - starting with the NLP domain.
GPT and GPT-2 came out in 2018 and 2019, respectively. The name means “generative pre-trained Transformers.” They are decoder-only models and use masked self-attention. This means that at a point in the output sequence, you can only attend to two input sequence vectors that came before that point in the sequence. While GPT embeddings can also be used for classification, the GPT approach is at the core of today’s most well-known large LLMs, such as chatGPT.
These models were trained on 8 million web pages. The largest model has 1.5 billion parameters. The task that GPT-2 was trained on is predicting the next word in all of this text on the web. They found that it works increasingly well with an increasing number of parameters.

BERT came out around the same time as Bidirectional Encoder Representations for Transformers. With 110 million parameters, it is an encoder-only Transformer designed for predictive modeling tasks and introduces the original concept of masked-language modeling. During training, BERT masks out random words in a sequence and has to predict whatever the masked word is.
T5 (Text-to-Text Transformer) came out in 2020. The input and output are both text strings, so you can specify the task that the model supposes to be doing. T5 has an encoder-decoder architecture. It was trained on the C4 dataset (Colossal Clean Crawled Corpus), which is 100x larger than Wikipedia. It has around 10 billion parameters.
The Moore’s Law for Foundation Models: Scaling Laws
Generally, scaling laws predict a continued improvement in model quality as we continue to scale up the computational budget (e.g., bigger models or more data). Open AI initially investigated the scaling laws of Transformer language models back in 2020 and showed that scaling laws are predictive of future performance. Their findings show that Performance ∝ Data Size x Parameter Size x Compute Size.
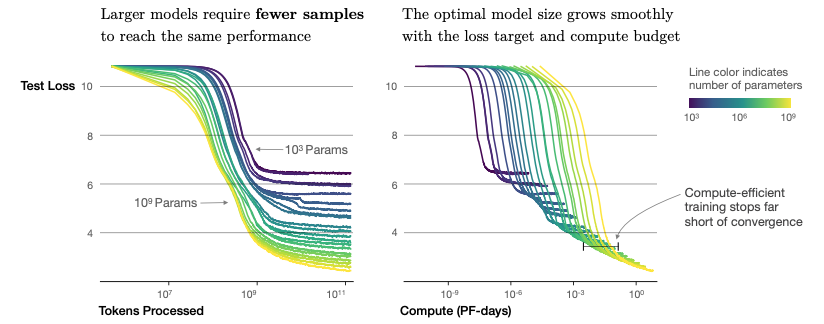
More specifically, the experiments reveal that the test loss follows a power law with respect to the model size, dataset size, and compute used for training, spanning trends over seven orders of magnitude. This suggests that the relationships between these variables can be described by simple equations, which can be used to optimize training configurations for large language models. Additionally, the experiments indicate that other architectural details, such as network width or depth, have minimal effects within a wide range.
Based on the experiments and derived equations, larger models are significantly more sample efficient. In other words, optimal compute-efficient training involves training very large models on a relatively modest amount of data and stopping significantly before convergence.

Since the publication of that Scaling Laws paper, there has been significant interest in scaling up language models. GPT-3 was one of the state-of-the-art models in 2020. It was 100 times larger than GPT/GPT-2, with 175 billion parameters. Due to its size, GPT-3 exhibits unprecedented capabilities in few-shot and zero-shot learning. The more examples you give the model, the better its performance will be. And the larger the model, the better its performance gets.
Google published an important paper titled "Emergent Abilities of Large Language Models," which explores the emergent abilities that are present in larger models but not in smaller ones. The paper examines research that analyzes the influence of scale, comparing models of different sizes trained with varying computational resources. For many tasks, the behavior of the model either predictably grows with scale or surges unpredictably from random performance to above random at a specific scale threshold (for instance, more than 70 billion parameters).

In 2022, DeepMind proposed the "Chinchilla" scaling laws to create compute-optimal models. This is a more accurate scaling law formula than the original one proposed by OpenAI.
- They trained over 400 language models with 70 million to 16 billion parameters on 5 billion to 500 billion tokens. By predicting the optimal amount of data given the number of model parameters, they derived formulas for the model and training set size. Most large language models are "undertrained," meaning they haven't seen enough data.
- To verify this, they trained another large model, Gopher, with 280 billion parameters and 300 billion tokens. With Chinchilla, they reduced the number of parameters to 70 billion while increasing data fourfold to 1.4 trillion tokens. Despite fewer parameters, Chinchilla exceeded Gopher's performance, suggesting that model size and training tokens are equally important.
Since the formal and empirical analysis of scaling laws, many more language models (LLMs) have been released. These models have achieved state-of-the-art few-shot results on many tasks by scaling model size, using sparsely activated modules, and training on larger datasets from more diverse sources. Notable examples include Megatron-LM (8.3B params), GLaM (64B params), LaMDA (137B params), Megatron-Turing NLG (530B params), and PaLM (540B params).
Scaling Vision Transformers from Google shows that the scaling law also applies to not only the NLP task but also the CV task. The authors conducted experiments with Vision Transformer models ranging from 5 million to 2 billion parameters, datasets ranging from 1 million to 3 billion training images, and compute budgets ranging from less than 1 TPUv3 core day to more than 10,000 core days. Their findings show that simultaneously scaling total compute and model size is effective. Increasing a model's size when additional compute is available is optimal. Moreover, Vision Transformer models with sufficient training data roughly follow a power law, and larger models perform better in few-shot learning.
Finally, the team at LAION AI attempted to reproduce scaling laws for the CLIP model family. Again, they find a power law relation between scale (model, data, and the number of samples seen) and downstream performance in a broad range of settings, including zero-shot classification, retrieval, few-shot and full-shot linear probing, and fine-tuning.
3 - The Rise of Large Vision-Language Models
Thanks to the Vision Transformer architecture, there has been increased interest in models that combine vision and language modalities. These hybrid vision-language models have demonstrated impressive capabilities in challenging tasks such as image captioning, image generation, and visual question answering. Typically, they consist of three key elements: an image encoder, a text encoder, and a strategy to fuse information from the two encoders. Let's review some of the most well-known models in vision-language model research over the past two years.
In 2021, OpenAI introduced CLIP (Contrastive Language–Image Pre-training). The input to CLIP is 400 million image-text pairs that were crawled from the internet. It encodes text using Transforms, encodes images using Vision Transformers, and applies contrastive learning to train the model. Contrastive training matches correct image and text pairs using cosine similarity.

With this powerful trained model, you can map images and text using embeddings, even on unseen data. There are two ways to do this. One way is to use a "linear probe" by training a simple logistic regression model on top of the features that CLIP outputs after performing inference. Alternatively, you can use a "zero-shot" technique that encodes all the text labels and compares them to the encoded image. The linear probe approach is slightly better.
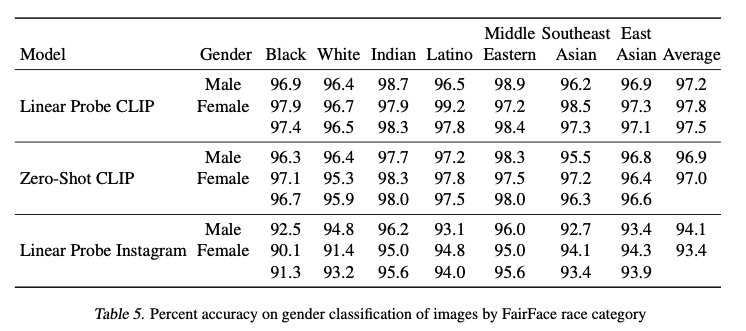
To clarify, CLIP does not directly go from image to text or vice versa. It uses embeddings. However, this embedding space is extremely useful for performing searches across modalities.
CoCa, or Contrastive Captioner, is another foundation model by Google that combines contrastive learning (CLIP) and generative learning (SimVLM). It uses an encoder-decoder architecture that has been modified and trained with both contrastive loss and captioning loss. This allows it to learn global representations from unimodal image and text embeddings, as well as fine-grained region-level features from the multimodal decoder.
In late 2022, DeepMind created a group of Visual Language Models called Flamingo. These models can do many different things, even with just a few examples of input and output. They have two parts: a vision model that can understand visual scenes, and a language model that helps with reasoning. The models use their pre-training knowledge to work together. Flamingo models can also take high-quality images or videos thanks to a Perceiver architecture (discussed in the section on Transformers variants) that can analyze a large number of visual input features and produce a small number of visual tokens.

Thanks to these new architectural innovations, the Flamingo models can connect strong pre-trained models for vision and for language, handle sequences of mixed visual and text data, and easily use images and videos as input. The Flamingo-80B, the biggest version with 80 billion parameters, set a new record in few-shot learning for many tasks that involve understanding language, images, and videos.
Microsoft, Google, and Open AI released their own versions of large vision-language models over the past few weeks, thereby propelling the trends toward multimodal AI further.
- Microsoft released Kosmos-1, a multimodal language model that can perceive different modalities, learn context and follow instructions. The model generates text based on the previous context and handles text and other modalities using a Transformer-based causal language model. It was trained using various types of data and has performed well in different scenarios, including understanding and creating language, recognizing images, and answering questions based on images.
- Google's PaLM-E is an embodied multimodal language model that can handle various reasoning tasks based on observations from different sources and using different embodiments, including internet-scale language, vision, and visual-language domains. The biggest PaLM-E model, PaLM-E-562B, has 562 billion parameters and can reason about different things without being trained beforehand, like telling jokes based on an image or doing robot tasks such as perceiving, talking, and planning.
- Lastly, OpenAI’s GPT-4 is a large multimodal model capable of processing image and text inputs and producing text outputs. It scored 90th percentile on a simulated bar exam and 99th percentile (with vision) on Biology Olympiad.
4 - The New Paradigm of Video Foundation Models
The Challenges of Video Understanding
Video understanding tasks are becoming increasingly important in our society. With the rise of video content on social media platforms and the increasing use of surveillance cameras in public spaces, there is a growing need for automated video understanding systems. However, despite the importance of this problem, it has received relatively little attention compared to text and image understanding tasks.
One reason why video processing hasn't received as much attention as text or image processing is due to the high computing burden it entails. Videos are much larger in size than text or images and require significantly more processing power to analyze. This issue is even more pronounced with a Transformer architecture, which has quadratic complexity with respect to token length.
To illustrate, assume a 10-minute video, which typically has 30 frames (images) per second. This means the video contains 10 * 3600 * 30 images or 1,080,000 (approximately 1 million) images. Given the quadratic complexity of the Transformer, the overall compute needed is 1 million squared (1e12).
Additionally, video understanding presents a unique challenge to temporal modeling. Unlike text and images, videos contain a temporal dimension that must be taken into account when analyzing them. This requires specialized techniques and models that are not commonly used in other modalities.
Finally, in addition to the visual information presented in video clips, there are synchronized audio cues that require additional processing. These audio cues can include sounds or conversations happening within the video, providing additional context and information to the viewer. It is important to note that these audio cues are often just as important as the visual information presented in the video, and should not be overlooked. Therefore, the processing of these audio cues is a crucial aspect of video analysis and should be given the same level of attention as visual analysis.
Although there are challenges, progress has been made in video understanding research. Since vision-language models are effective and multimodal trends are emerging, several language and vision foundation models have been proposed to address this problem. An active research community is working on this topic. However, more work is needed before we can develop video understanding systems that are robust and reliable enough to be used in real-world applications.
Emerging Large Video Models

In 2019, Google introduced VideoBERT, which applied self-supervision to video. It used three pre-existing methods: automatic speech recognition, vector quantization for spatiotemporal visual features, and a BERT model for sequences of tokens. These worked together to model the relationship between visual and linguistic domains. To make BERT work with videos, the authors turned the raw video data into "visual words" using vector quantization. This helps the model focus on important parts of the video and how they change over time. VideoBERT outperformed other models in video captioning tests.
"All-In-One" is a video-language model designed for pre-training that captures video-language representations from raw visual and textual signals in a unified backbone architecture. It uses a temporal token rolling operation to capture temporal representations of sparsely sampled frames without adding extra parameters or increasing time complexity. This model performs well on four downstream video-language tasks: video question answering, text-to-video retrieval, multiple-choice, and visual commonsense reasoning.
Video recognition involves identifying and categorizing objects, actions, and events within a video. It has many practical applications, such as in security systems, autonomous vehicles, and entertainment industries. As such, it is an area of research that continues to evolve, with new developments occurring regularly.
Video MAE is a self-supervised video pre-training method that unlocks the potential of the vanilla Vision Transformer for video recognition. It masks random tubes and reconstructs the missing ones with an asymmetric encoder-decoder architecture. The authors introduced two key designs - an extremely high masking ratio and a tube masking strategy - that encourage VideoMAE to learn more representative features, thereby addressing challenges with temporal redundancy and correlation.

We can learn a new way to recognize videos by using natural language supervision, which is similar to how CLIP learns to represent visual language using large amounts of image-text data from the web. Once we have pre-trained the model, we can use natural language to refer to the visual concepts that the model has learned, which allows us to easily transfer the model to other tasks with little or no extra training.
Microsoft's X-Clip framework adapts language-image models to general video recognition. It has two components: a cross-frame communication Transformer and a multi-frame integration Transformer. The former allows frames to exchange information using message tokens, while the latter transfers frame-level representations to video-level. X-CLIP uses video content information to enhance text prompting via a video-specific prompting scheme. In fully-supervised, zero-shot, and few-shot experiments, X-CLIP performs well despite limited labeled data.

Compared to language and image foundation models, current video foundation models have limited support for video and video-language tasks. However, a new work called InternVideo combines two popular self-supervised learning paradigms: masked video modeling and multimodal contrastive learning. It uses learnable interactions to derive new features from these two Transformers, combining the benefits of both generative and contrastive learning.
InternVideo outperformed other models on a video understanding benchmark that includes tasks in action understanding, video-language alignment, and open-world video applications. These tasks represent the core abilities of generic video perception.
Conclusion
Foundation models are becoming multi-modal, whether you are ready or not. As foundation models will eventually serve as the basis of all AI-powered software, developers will increasingly start with pre-trained foundation models and then fine-tune them on narrow tasks. However, the most difficult situations for these models are the "long-tail" events they have not seen before. These long-tail events are even more complex to solve under multi-modal settings.
At Twelve Labs, we are building foundation models for long-tail multimodal video understanding. Our vision is to help developers build programs that can see, listen, and understand the world as we do by providing them with the most powerful video-understanding infrastructure. We have many more thoughts on multi-modal large neural networks, but this post is already quite lengthy. If you are interested in chatting about this, sign up as a Beta user! Additionally, join our Discord community to discuss all things Multimodal AI!
Thanks to Aiden Lee for providing the sources and proofreading various drafts of this massive article!
Generation Examples
Comparison against existing models
Related articles

Our video-language foundation model, Pegasus-1. gets an upgrade!


This blog post introduces Marengo-2.6, a new state-of-the-art multimodal embedding model capable of performing any-to-any search tasks.

.png)
This article introduces the suite of video-to-text APIs powered by our latest video-language foundation model, Pegasus-1.


Twelve Labs will co-host our first in-person hackathon in San Francisco!