








It’s an exciting time to be involved in video understanding. Over the past decade, there has been tremendous progress in this field thanks to the development of cutting-edge neural network architectures, and it continues to show no signs of slowing down. We have seen a considerable surge recently with advances such as facial recognition software and video creation tool—allowing us to gain more insight from our media than ever before. But these are just scratching at the surface of what could be done; there is so much more potential yet to be realized when it comes to extracting engaging clips within videos or even creating new interactive experiences based on existing footage.
In our first article on how foundation models are going multimodal, we discussed the unique challenges of handling the video modality. This article will further investigate this topic by reviewing how far video understanding research has come, what potential remains untapped, and where it is headed in the future.
1 - The Past: Solving Low-Level Video Perception Tasks
It’s important to highlight the difference between video perception and video understanding tasks.
Video perception tasks involve extracting low-level features from video data, such as color, texture, and motion. These tasks are often based on computer vision techniques, and the goal is to provide a representation of the visual content of the video that can be further analyzed.
On the other hand, video understanding tasks involve higher-level processing of video data, such as recognizing objects, actions, or events in the video. These tasks often require more sophisticated models that can capture contextual information and temporal relationships between frames.
In general, video perception is a prerequisite for video understanding, as it provides the input data necessary for higher-level processing. Since 2013, deep learning and computer vision have become increasingly popular, leading to more people using AI for video perception tasks. This has been traditionally accomplished through convolutional neural networks (ConvNet) that can detect, track, and segment objects.
1.1 - Video Object Detection
Video object detection is a fascinating field of study that has been gaining more and more attention in recent years. This technique involves detecting objects in a video stream instead of the more traditional approach of detecting objects in still images. Detecting objects in a video stream involves analyzing a sequence of frames and identifying objects that appear in those frames. This can be a complex process, as the objects may move, change their size, or be partially obscured by other objects in the video.
However, with the help of advanced computer vision techniques and machine learning algorithms, video object detection has become a highly effective tool for a wide range of applications, from security and surveillance to robotics and autonomous vehicles. Neural network architectures like RetinaNet, YOLO (You Only Look Once), CenterNet, SSD (Single Shot Multibox Detector), and Region proposals (R-CNN, Fast-RCNN, Faster RCNN, Cascade R-CNN) are widely used in this task.
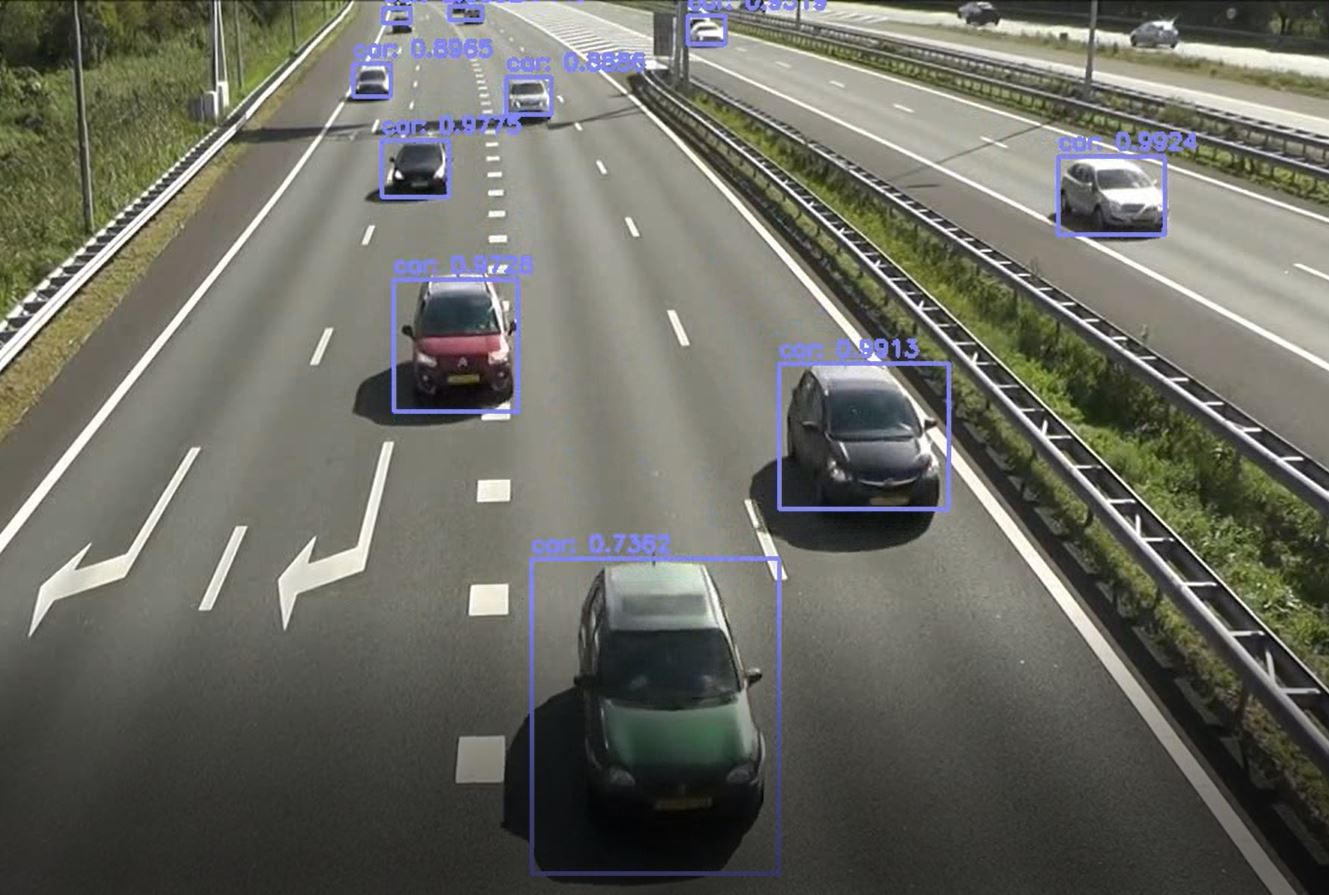
Previous methods for detecting objects in videos involved analyzing each image frame separately. However, this approach is slow and inefficient because it doesn't consider the similarities between adjacent frames that can lead to repeated feature extraction. Some frames may also be of poor quality due to movement, blurriness, occlusion, or changes in position over time, which can result in low accuracy when detecting objects in such frames.
To overcome these shortcomings, researchers are now focusing on deep learning solutions that exploit the consistency of video data over time. As shown in the figure below, based on the utilization of the temporal information and the aggregation of features extracted from video snippets, video object detectors can be divided into flow-based (Deep Feature Flow, Flow-Guided Feature Aggregation, Impression Network), LSTM-based (Looking Fast and Slow, LSTM-SSD, LSTMNet), attention-based (Relation Distillation Network, Memory Enhanced Global-Local Aggregation, Progressive Sparse Local Attention), tracking-based (Detect or Track, Cascaded Tracked Detector, Cooperative Detection and Tracking), and other methods that combine multiple methods above (Spatial-Temporal Sampling Network, Spatial-Temporal Memory Network).

1.2 - Video Object Tracking
Video object tracking estimates the trajectories of objects over time in a video sequence. This technique is important in many fields, such as security, entertainment, and sports. By accurately tracking the movements of objects within a video, we can analyze behavior patterns, detect anomalies, predict future movements, and more. For example, in security, video object tracking can help identify potential threats by detecting suspicious behavior or tracking the movement of individuals. In entertainment, video object tracking can be used to create special effects or enable interactive experiences. In sports, video object tracking can help coaches analyze the performance of individual players or entire teams, providing valuable insights into strategic planning and player development.

There are two main approaches: detection-based and matching-based.
Detection-based methods, such as SORT or Deep SORT, first detect objects in each frame and then associate them across frames based on various criteria. While they are robust to occlusions and appearance changes, they may suffer from false positives and require a high-quality detector.
Matching-based methods, such as Siamese networks or correlation filters, learn a similarity metric across frames and use it to match objects based on their features. While they are more efficient and can handle partial occlusions, they may struggle with long-term tracking and require fine-tuning for each target class.
Video object tracking is a challenging task that requires a careful choice of methods and parameters for each application due to the challenges of occlusions, illumination changes, and motion blur. Detection-based methods are currently the most accurate, but they may have limitations in terms of scalability and robustness in complex scenarios. Matching-based methods may provide a more efficient and generic solution but require ongoing refinement.
1.3 - Video Instance Segmentation
Video instance segmentation is a challenging task that involves simultaneously detecting, segmenting, and tracking instances in a video. This extends the image instance segmentation problem to the video domain. This task opens up possibilities for applications that require video-level object masks, such as video editing, autonomous driving, and augmented reality.
For example, the illustration of video instance segmentation below shows image frames in a video, video instance annotations, and video instance predictions. It shows how video instance segmentation can be used to segment objects of interest in a video sequence.
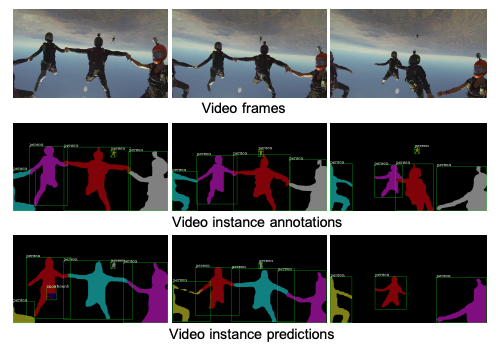
Video instance segmentation is more challenging than image instance segmentation in that it requires not only instance segmentation on individual frames but also the tracking of instances across frames. On the other hand, video content contains richer information than a single image, such as motion patterns of different objects and temporal consistency, and thus provide more cues for object recognition and segmentation.
There are two main methods of doing video instance segmentation: two-stage and one-stage.
Two-stage methods, like Mask R-CNN or MaskTrack R-CNN, first detect object proposals and then use a mask head to generate instance segmentation masks. While they achieve state-of-the-art performance, they can be computationally expensive and slow.
One-stage methods, such as YOLACT or HTC, combine detection and segmentation in a single stage and use anchor-free designs to improve speed and accuracy. However, they may struggle with fine-grained segmentation and have a higher false positive rate than two-stage methods.
To choose the best approach for your application, consider trade-offs between accuracy, speed, and memory requirements. Two-stage methods may be more accurate but slower, while one-stage methods may be faster but less accurate.
Recently, there has been a new tool called Track-Anything, which is designed for video object tracking and segmentation. It is developed upon SAM (Segment Anything Model) and can specify anything to track and segment via user clicks only.

For context, SAM is a foundation model for image segmentation. It focuses on promptable segmentation tasks, using prompt engineering to adapt to diverse downstream segmentation problems. Trained on over 1 billion masks on 11M licensed images (the biggest semantic segmentation dataset ever released), SAM can complete a bunch of zero-shot tasks such as edge detection, object proposal generation, and instance segmentation.
Track-Anything brings the power of SAM to the video modality. During tracking, users can flexibly change the objects they want to track or correct the region of interest if there are any ambiguities. These characteristics make Track-Anything suitable for:
- Video object tracking and segmentation with shot changes.
- Visualized development and data annotation for video object tracking and segmentation.
- Object-centric downstream video tasks, such as video in-painting and editing.

Given this development, we expect to see more foundation models for video segmentation and tracking coming soon.
1.4 - The Limitations of Video Perception
While video perception tasks have made significant progress in recent years, there are still some limitations to their effectiveness.
One major limitation of video perception tasks is the difficulty of defining new classes or labels when new tasks are introduced. This is because video perception models are often trained on a fixed set of classes or labels, and it can be challenging to modify the model to recognize new objects. This can be especially problematic in dynamic environments where new objects are introduced frequently, such as in robotics or autonomous vehicles. To address this limitation, researchers are exploring ways to make video perception models more flexible and adaptable, such as through incremental learning or zero-shot learning.
Another limitation of video perception tasks is their robustness when there is a domain shift. Video perception models are often trained on a specific dataset, and their performance may suffer when applied to out-of-distribution video data. This can be especially problematic when the video content contains variations in lighting, motion, or other factors that are not represented in the training dataset. To address this limitation, researchers are figuring out how to make video perception models more robust and generalizable, such as through domain adaptation or transfer learning.
2 - The Present: Handling High-Level Video Understanding Tasks
Video understanding technology has come a long way since its inception, evolving from low-level video detection and segmentation tasks to higher-level video understanding tasks. The approaches mentioned above were limited to narrow tasks and had inefficiencies that often resulted in missed tags, mislabeled objects, and inaccuracies. Present approaches have evolved to handle broader tasks such as classification, search, question answering, and captioning - thereby providing more opportunities for harnessing their power.
2.1 - Video Classification
Video classification is the process of analyzing and categorizing video content. This involves recognizing objects, people, actions, or scenes and classifying them into predefined categories like sports, news, music, entertainment, or education. To do this, you would design and implement systems that extract and recognize video features (color, motion, spatial layout, and audio content) and use them to improve classification accuracy.
Action recognition and action localization are two important research subdomains of video classification.
Action Recognition

Video action recognition is the task of identifying actions performed by a subject in a given video sequence. This involves analyzing video frames to identify the type of action being performed and when it starts and ends. Video action recognition has applications in various fields, including video surveillance and sports analysis. In surveillance, it can detect abnormal behavior or suspicious activities, while in sports, it can extract key frames from a video to track athletes' movements and correct their form.
Developing effective video action recognition algorithms faces several major challenges:
- First, videos capturing human actions have both strong intra- and inter-class variations. People can perform the same action at different speeds and from various viewpoints.
- Second, recognizing human actions requires a simultaneous understanding of both short-term action-specific motion information and long-range temporal information. A sophisticated model may be necessary to handle different perspectives instead of using a single convolutional neural network.
- Finally, the computational cost is high for both training and inference, which hinders the development and deployment of action recognition models.
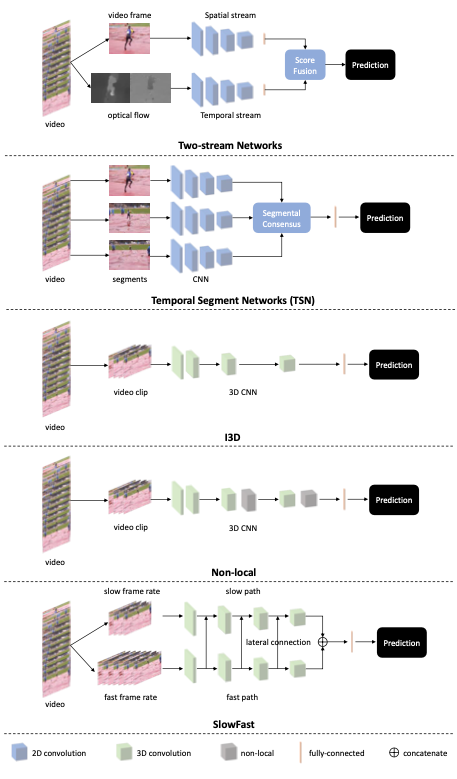
Thanks to the availability of large-scale datasets and the rapid progress in deep learning, there has been a rapid growth in deep learning-based models for recognizing video actions. For instance, ConvNet was the default of choice to model video temporal information, with models such as DeepVideo, Two-Stream Networks, Non-Local, and SlowFast. But recently, researchers have focused on the Transformer architecture thanks to its computational efficiency to scale to even larger datasets, with models such as Video Swin Transformer and TimeSformer.
Action Localization

Action localization (also known as spatiotemporal action recognition) is the task of classifying what action is being performed in a sequence of frames in a video and localizing each action in both space and time. The localization can be visualized using bounding boxes or masks. There has been an increased interest in this task in recent years due to the increased availability of computing resources and new advances in ConvNet architectures.
Action localization faces the usual challenges seen in action recognition, such as tracking the action throughout the video and localizing the timeframe when the action occurs. However, there is an additional set of challenges, including but not limited to:
- Background clutter or object occlusion in the video
- Spatial complexity in scenes with respect to the number of candidate objects
- Linking actions between frames in the presence of irregular camera motion
- Predicting the optical flow of the action
There are several methods and techniques used to address action localization in videos. Most rely on clever usage of similar features, including RGB pixel values, optical flow, and skeleton graphs. These include action proposal networks, figure-centric models, deformable parts models, graph-based models, and spatiotemporal convolutions.
2.2 - Video-Text Retrieval

Video-text retrieval aims to find the most relevant video related to the semantics in a given sentence (and vice versa). It requires analyzing the content of a large number of video-text pairs, fully excavating the multi-modal information involved, and judging whether the two modalities can be aligned. Given the explosive growth of multimedia information, video-text retrieval is a powerful tool to help people quickly search for an item that meets their needs.
In general, the video-text retrieval task can be divided into four parts: video representation extraction, textual representation extraction, feature embedding and matching, and objective functions.
Video representation extraction captures the video feature representation. These extractors can be either spatial or temporal according to the spatiotemporal property. Notably, Transformer-based methods (such as CLIP4Clip, CLIP2Video, Cooperative Hierarchical Transformer, X-CLIP, Frozen In Time, and TimeSformer) have shown excellent performance in capturing both spatial and temporal representations.
In addition, since multimodality information is involved in videos (e.g., motion, audio, or face features), additional experts are typically used to extract features for each modality, which are then aggregated to generate a more comprehensive video representation. Examples include Collaborative Experts and Mixture-of-Embeddings Experts.
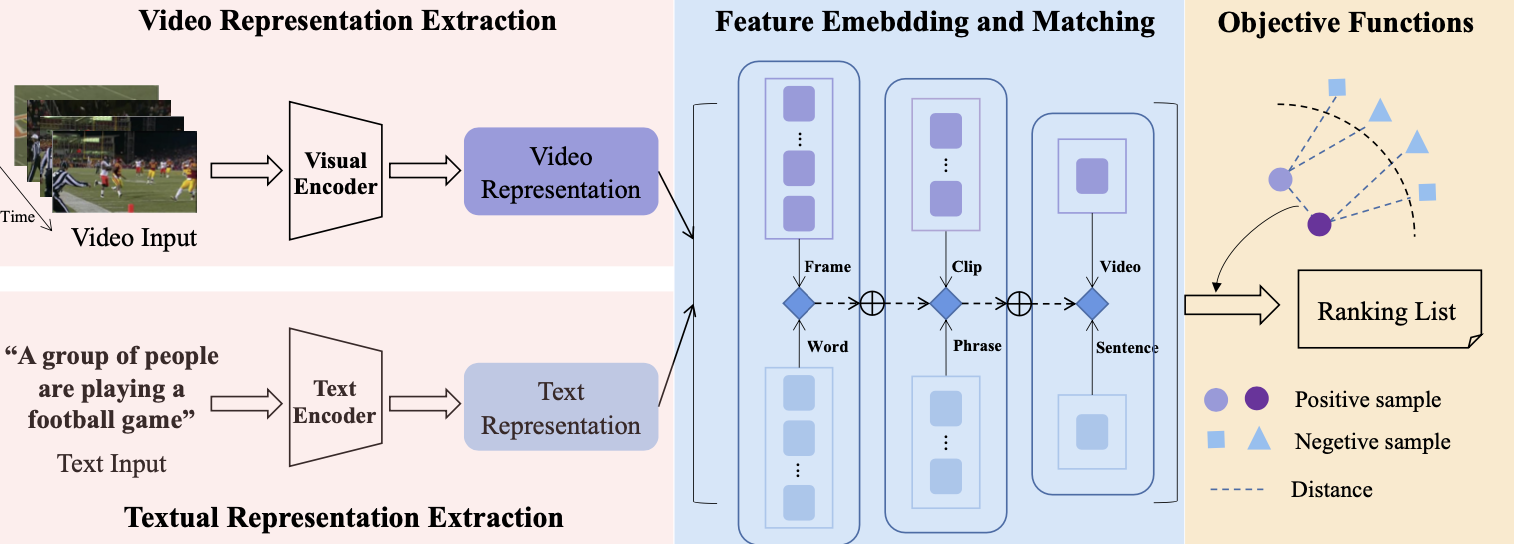
Textual representation extraction refers to extracting textual features. The extractors are mainly built upon pre-trained language models such as BERT, RoBERTa, ALBERT, and DistilBERT.
The video-text retrieval task has made rapid progress in recent years. However, some inherent challenges remain, such as how to extract complete and robust video features, how to address the cross-modal gap between video and text retrieval, and how to reduce the training time and retrieval efficiency of these models.
2.3 - Video Question-Answering
Video question-answering (Video QA) predicts the right answer based on a question and a video. Video QA has become more popular thanks to research in vision-language understanding. Its promise is to develop AI that can communicate using natural languages with the dynamic visual world. However, the QA model faces a big challenge in comprehensively understanding videos to answer questions correctly. This includes not only recognizing visual objects, actions, activities, and events, but also inferring their semantic, spatial, temporal, and causal relationships.

VideoQA tasks can be mainly divided into two types: multi-choice QA and open-ended QA.
For multi-choice QA, the models are given several candidate answers for each question and must select the correct one.
For open-ended QA, the problem can involve classification (the most popular), generation (word-by-word), or regression (for counting), depending on the specific datasets. In classification-based open-ended QA, the model classifies a video-question pair into a pre-defined global answer set. In generation-based open-ended QA, the model predicts the next word in a vocabulary set to form the answer of a certain length. In regression-based open-ended QA, the model computes an integer-valued answer to be close to the ground truth.

As illustrated above, a common framework for video question answering comprises four components: a video encoder, a question encoder, cross-modal interaction, and an answer decoder.
- The video encoder extracts features from raw videos by jointly capturing frame appearance and clip motion. These features are typically obtained using pre-trained 2D or 3D neural networks.
- The question encoder extracts token-level representations, such as GloVe and BERT features.
- Next, a sequential model (such as Transformer) processes the sequential data of vision and language to facilitate cross-modal interaction.
- Finally, the answer decoder can be a one-way classifier that selects the correct answer from provided multiple choices (for multi-choice QA), an n-way classifier that selects an answer from a pre-defined global answer set, or a language generator that generates an answer word by word (for open-ended QA).
Compared to other video tasks, question-answering requires a comprehensive understanding of videos at different levels of granularity, including fine-grained and coarse-grained in both temporal and spatial domains, as well as factoid and inference questions.

Various Video QA techniques include Memory Networks, Transformers, Graph Neural Networks, Modular Networks, and Neuro-Symbolic architectures. Notably, Transformer-based architectures such as PSAC, MMFT-BERT, ClipBERT, Just Ask, MERLOT and VIOLET have demonstrated powerful capabilities for fine-grained video reasoning while requiring fewer computational resources and providing better interpretability.
2.4 - Video Captioning
Video captioning is the process of describing the content of a video sequence in order to capture its semantic relationships and meanings. The number of applications that could be beneficial with this technology is enormous, for instance, content retrieval systems, smart video surveillance, and computer-human interface systems, among others. Compared to image captioning, video captioning is significantly more challenging because the time variable becomes crucial to determine the relationship between objects, detecting the actions, and so on.
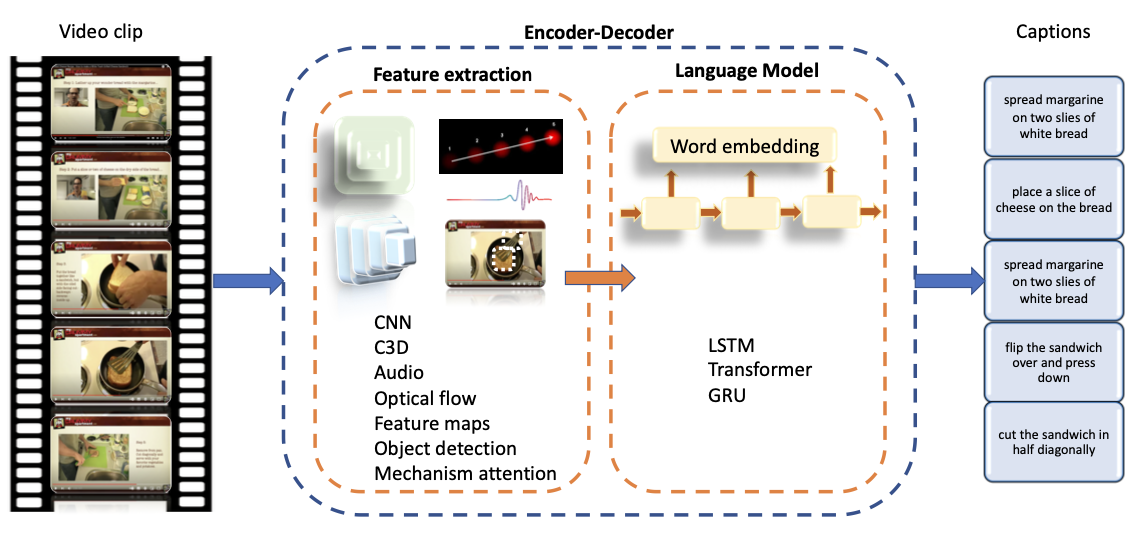
The figure above provides a general overview of a typical solution for the video captioning task, which uses an encoder-decoder framework (the most productive and beneficial sequence-to-sequence modeling technique).
- The visual encoder extracts video features, which the decoder then translates into a text format to generate descriptions. It obtains these features using different techniques such as 2D or 3D ConvNet and attention mechanism (for temporal and spatial characteristics). In addition, it can also consider other features, such as audio, optical flow, and feature maps.
- The language decoder performs the translation task using architecture such as RNNs, LSTM, GRU, and Transformers.
- During training, the model gets better and better at generating captions until they are very close to the provided ones. More specifically, the attention mechanism helps the model learn more information to make better predictions for the sentences.

While the early methods rely on the standard encoder-decoder framework, the rise of the Transformer architecture has brought great innovation to recent video captioning techniques. These techniques use different Transformer variants, including Universal Transformers, Masked Transformers, Two-View Transformers, Bidirectional Transformers, and Vision Transformers.
While descriptions made by these models have gotten better, they are still not the same as ones made by humans. To improve those machine-made captions, it's important to include human knowledge. When a model learns from multiple sources like video, audio, and subtitles, it can better understand and explain what's happening, leading to better captions overall.
3 - The Future: Going Multimodal With Video Foundation Models
Foundation models have become very popular in Natural Language Processing and Computer Vision, but their potential for video understanding has not been fully realized yet. This is due in part to the challenges of processing and analyzing large amounts of video data efficiently, as well as the difficulty of combining different modalities effectively to improve video understanding. However, there is a growing interest in the applications of video understanding in real-world products, driven by the diverse use cases and needs of developers in various industries such as entertainment, education, and surveillance.
One area of research that shows promise for improving video understanding is the development of hybrid models that combine the strengths of different modalities, such as audio, textual, and visual. These “multimodal” foundation models can leverage techniques like unsupervised learning and self-supervised learning to extract features from different modalities and create a more holistic understanding of the video content.
Let’s briefly highlight different multimodal video foundation models coming out very recently:
3.1 - VideoCoCa
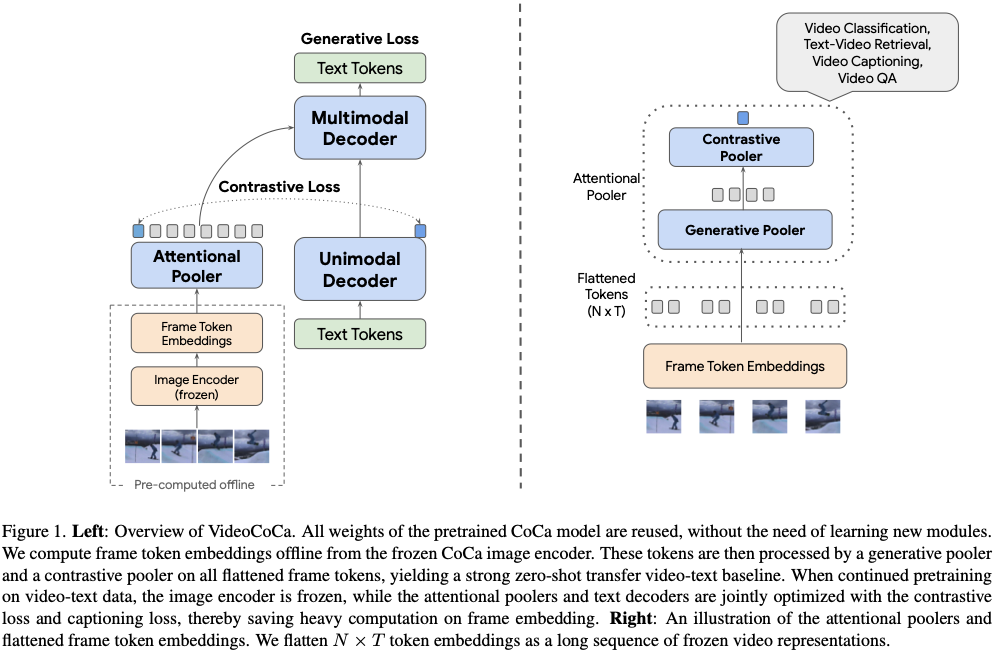
VideoCoCA is an approach to video-text modeling that leverages existing contrastive captioners (aka, CoCa) without requiring fine-tuning. The model achieves this by using contrastive captioning models to generate candidate sentences, which are then scored by a Transformer-based model. The Transformer-based model is trained to score the candidate sentences based on their relevance to the target video.
The authors tested VideoCoCa on various data sets and achieved competitive performance compared to state-of-the-art methods in zero-shot video classification, zero-shot video-text retrieval, video captioning, and video question answering (after being fine-tuned). They also conducted ablation studies and showed that contrastive captioning is a critical component of VideoCoCa.
3.2 - Merlot-Reserve

MERLOT Reserve is a model that learns multimodal neural script knowledge representations of video by jointly reasoning over video frames, text, and audio. The model is designed to represent videos over time and across modalities (including audio, subtitles, and video frames). The model is trained on over 20 million YouTube videos through a new contrastive masked span learning objective to learn from text and audio self-supervision. As a result, it can capture the semantic and temporal relationships between different elements of a video, which allows it to learn a rich representation of video content that can be used for a wide range of video understanding tasks.
The authors evaluated MERLOT Reserve on multiple benchmarks and showed that it outperforms state-of-the-art methods and achieves high performance even on cross-domain datasets (visual commonsense reasoning, situated reasoning, action anticipation, and video QA). They also conducted ablation studies and showed that pre-training on script knowledge is critical for MERLOT Reserve. They further analyzed the learned representations of MERLOT Reserve and showed that it could capture meaningful semantic and syntactic structures of video content.
3.3 - Vid2Seq

Vid2Seq is a single-stage dense video captioning model that has been pre-trained on narrated videos. The model takes frames and transcribed speech from an untrimmed video that is several minutes long as the input. It then outputs dense event captions together with their temporal localization in the video by predicting a single sequence of tokens. The architecture of the model augments the T5 language model with special time tokens, allowing it to seamlessly predict event boundaries and textual descriptions in the same output sequence.
Vid2Seq is pre-trained using unlabeled narrated videos in HowTo100M, which are easily available at scale. In particular, the authors use the YT-Temporal-1B dataset, which includes 18 million narrated videos covering a wide range of domains. Given these unlabeled narrated videos, the authors reformulated sentence boundaries of transcribed speech as pseudo-event boundaries and used the transcribed speech sentences as pseudo-event captions.
Vid2Seq achieves state-of-the-art performance on standard dense event captioning benchmarks, including ActivityNet-Captions, YouCook2, and Video Timeline Tags. It also generalizes well to the few-shot dense video captioning setting, the video paragraph captioning task, and the standard video captioning task.
Conclusion
Video understanding technology has made significant progress in the past decade, thanks to the development of cutting-edge neural network architectures. In the past, video understanding was limited to low-level perception tasks such as object detection, segmentation, and tracking. However, present approaches can handle high-level understanding tasks such as classification, search, question answering, and captioning, providing more opportunities to harness their power. Furthermore, the future of video understanding technology is promising, with multimodal video foundation models on the horizon.
At Twelve Labs, we are developing foundation models for multimodal video understanding. Our goal is to help developers build programs that can see, listen, and understand the world as we do with the most advanced video-understanding infrastructure. If you would like to learn more, please sign up at https://playground.twelvelabs.io/ and join our Multimodal Minds Discord community to chat about all things Multimodal AI!
Generation Examples
Comparison against existing models
Related articles

A beginner guide to video understanding for M&E with MASV and Twelve Labs


Our video-language foundation model, Pegasus-1. gets an upgrade!


This blog post introduces Marengo-2.6, a new state-of-the-art multimodal embedding model capable of performing any-to-any search tasks.

.png)
This article introduces the suite of video-to-text APIs powered by our latest video-language foundation model, Pegasus-1.
