









To Jae Lee, a data scientist by training, it never made sense that video — which has become an enormous part of our lives, what with the rise of platforms like TikTok, Vimeo and YouTube — was difficult to search across due to the technical barriers posed by context understanding. Searching the titles, descriptions and tags of videos was always easy enough, requiring no more than a basic algorithm. But searching within videos for specific moments and scenes was long beyond the capabilities of tech, particularly if those moments and scenes weren’t labeled in an obvious way.
To solve this problem, Lee, alongside friends from the tech industry, built a cloud service for video search and understanding. It became Twelve Labs, which went on to raise $17 million in venture capital — $12 million of which came from a seed extension round that closed today. Radical Ventures led the extension with participation from Index Ventures, WndrCo, Spring Ventures, Weights & Biases CEO Lukas Biewald and others, Lee told TechCrunch in an email.
The vision of Twelve Labs is to help developers build programs that can see, listen, and understand the world as we do by giving them the most powerful video understanding infrastructure.
“The vision of Twelve Labs is to help developers build programs that can see, listen, and understand the world as we do by giving them the most powerful video understanding infrastructure,” Lee said.
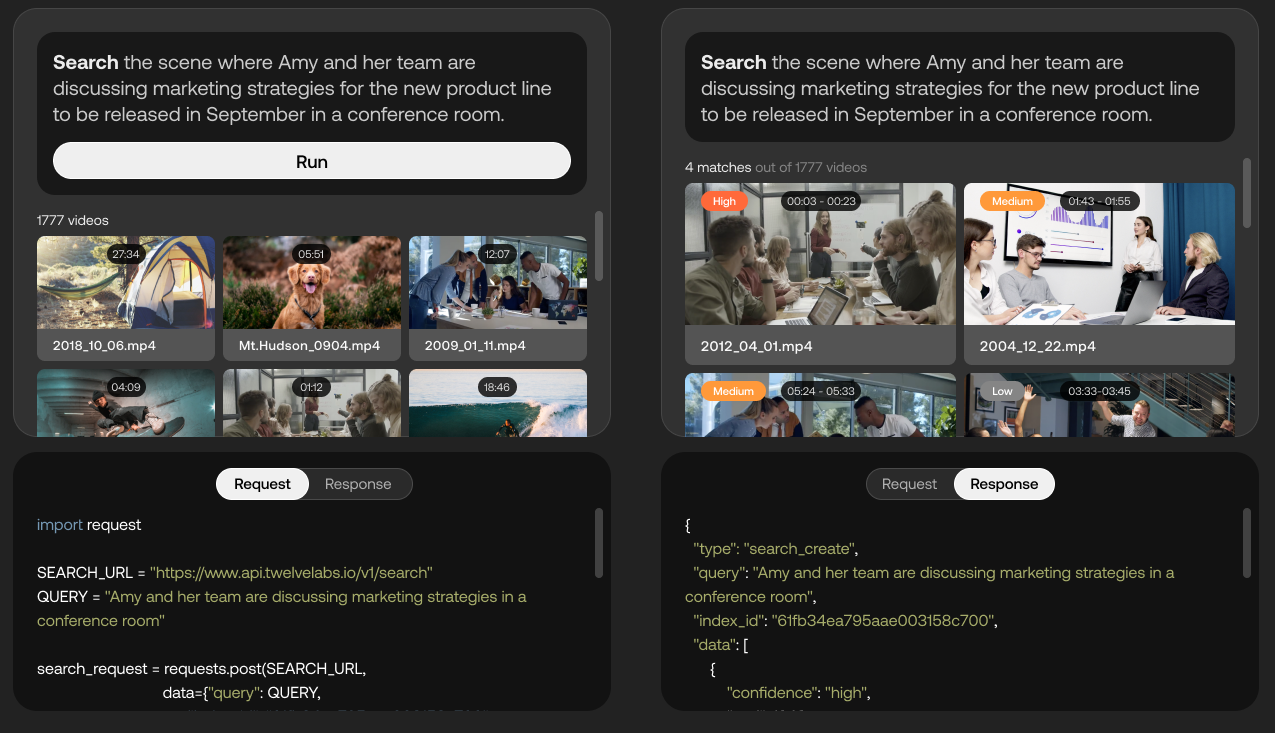
Twelve Labs, which is currently in closed beta, uses AI to attempt to extract “rich information” from videos such as movement and actions, objects and people, sound, text on screen, and speech to identify the relationships between them. The platform converts these various elements into mathematical representations called “vectors” and forms “temporal connections” between frames, enabling applications like video scene search.
“As a part of achieving the company’s vision to help developers create intelligent video applications, the Twelve Labs team is building ‘foundation models’ for multimodal video understanding,” Lee said. “Developers will be able to access these models through a suite of APIs, performing not only semantic search but also other tasks such as long-form video ‘chapterization,’ summary generation and video question and answering.”
Google takes a similar approach to video understanding with its MUM AI system, which the company uses to power video recommendations across Google Search and YouTube by picking out subjects in videos (e.g., “acrylic painting materials”) based on the audio, text and visual content. But while the tech might be comparable, Twelve Labs is one of the first vendors to market with it; Google has opted to keep MUM internal, declining to make it available through a public-facing API.
That being said, Google, as well as Microsoft and Amazon, offer services (i.e., Google Cloud Video AI, Azure Video Indexer and AWS Rekognition) that recognize objects, places and actions in videos and extract rich metadata at the frame level. There’s also Reminiz, a French computer vision startup that claims to be able to index any type of video and add tags to both recorded and live-streamed content. But Lee asserts that Twelve Labs is sufficiently differentiated — in part because its platform allows customers to fine-tune the AI to specific categories of video content.

“What we’ve found is that narrow AI products built to detect specific problems show high accuracy in their ideal scenarios in a controlled setting, but don’t scale so well to messy real-world data,” Lee said. “They act more as a rule-based system, and therefore lack the ability to generalize when variances occur. We also see this as a limitation rooted in lack of context understanding. Understanding of context is what gives humans the unique ability to make generalizations across seemingly different situations in the real world, and this is where Twelve Labs stands alone.”
Beyond search, Lee says Twelve Labs’ technology can drive things like ad insertion and content moderation, intelligently figuring out, for example, which videos showing knives are violent versus instructional. It can also be used for media analytics and real-time feedback, he says, and to automatically generate highlight reels from videos.
A little over a year after its founding (March 2021), Twelve Labs has paying customers — Lee wouldn’t reveal how many exactly — and a multiyear contract with Oracle to train AI models using Oracle’s cloud infrastructure. Looking ahead, the startup plans to invest in building out its tech and expanding its team. (Lee declined to reveal the current size of Twelve Labs’ workforce, but LinkedIn data shows it’s roughly 18 people.)
“For most companies, despite the huge value that can be attained through large models, it really does not make sense for them to train, operate and maintain these models themselves. By leveraging a Twelve Labs platform, any organization can leverage powerful video understanding capabilities with just a few intuitive API calls,” Lee said. “The future direction of AI innovation is heading straight towards multimodal video understanding, and Twelve Labs is well positioned to push the boundaries even further in 2023.”
Generation Examples
Comparison against existing models
Related articles

A Twelve Labs and MindsDB Tutorial


A Twelve Labs and FiftyOne Plugin Tutorial

Twelve Labs will co-host our first in-person hackathon in San Francisco!


This article examines the technical challenges of video data management and looks at how ApertureDB and Twelve Labs help solve them