








Welcome to the exciting world of Multimodal AI! The 23Labs Hackathon, hosted by Cerebral Valley, Eleven Labs, and Twelve Labs, is set to take place on October 14 and 15 at Shack 15, located in the historic Ferry Building in San Francisco. This event aims to bring together creative minds and innovative technologies to explore the potential of Multimodal AI, a rapidly emerging field that combines voice, video, and other modalities to create groundbreaking applications.
Participants will be granted API access to Eleven Labs, Twelve Labs, and other partners, allowing them to build creativity-focused tools with hands-on support from the teams behind these cutting-edge startups. With over $10K in cash prizes and credits up for grabs, this hackathon promises to be an unforgettable experience for all involved.
Overview of ElevenLabs and Twelve Labs
Established in 2022, ElevenLabs is a voice technology research company developing world-leading text-to-speech software for publishers and creators. The company’s mission is to make content universally accessible.
Here are the key features of the software built by ElevenLabs:
- Text-to-speech technology using pre-made synthetic voices
- Professional voice cloning tools
- The ability to design new AI voices
- The ability to ‘speak’ text in up to 30 languages
- Tools to generate and edit long-form audio
Founded in 2021, Twelve Labs builds a video understanding platform that uses AI to power many downstream tasks, such as natural language search, zero-shot classification, and text generation from video. These capabilities are built on top of the platform’s state-of-the-art multimodal foundation model for videos. The company's vision is to help developers build programs that can see, listen, and understand the world as we do by giving them the most powerful video understanding infrastructure.
Here are the key features of the Twelve Labs platform:
- Capture context with Index API: Index once, do everything. Create contextual video embeddings to search, classify, and summarize content in seconds.
- Find anything with Search API: Use everyday language for lightning-fast, context-aware searches that pinpoint the exact scenes you need.
- Categorize videos with Classify API: Instantly sort and categorize content. Classify content with any taxonomy of your own. No training required.
- Generate text with Generate API: Generate text about your videos by prompting. Ask the model to write reports, get summaries, and come up with chapters - whatever you need.
Pushing the Frontiers of Multimodal AI
ElevenLabs’ Text-to-Speech Model
ElevenLabs’ research teams have pioneered cutting edge text-to-speech capabilities which focus on combining novel approaches to synthesizing speech to achieve ultra-realistic delivery. The ElevenLabs model is able to understand the relationship between words and adjust the delivery based on context; enabling nuance and emotion to be conveyed. This means the AI voices don’t sound robotic, but human. This represents a global breakthrough for text-to-speech technology.
Traditional speech generation algorithms produced utterances on a sentence-by-sentence basis. This is computationally less demanding but immediately comes across as robotic. Emotions and intonation often need to stretch and resonate across a number of sentences to tie a particular train of thought together. Tone and pacing convey intent which is really what makes speech sound human in the first place. So rather than generate each utterance separately, ElevenLabs’ model takes the surrounding context into account, maintaining appropriate flow and prosody across the entire generated material. This emotional depth, coupled with prime audio quality, provides users with the most genuine and compelling narrating tool out there.
Twelve Labs’ Multimodal Language Model
When you watch a movie, you typically use multiple senses to experience it. For example, you use your eyes to see the actors and objects on the screen and your ears to hear the dialogue and sounds. Using only one sense, you would miss essential details like body language or conversation. This is similar to how most large language models operate - they are usually trained to understand only text. However, they cannot integrate multiple forms of information and understand what's happening in a scene.
When a language model processes a form of information, such as a text, it generates a compact numerical representation that defines the meaning of that specific input. These numerical representations are named unimodal embeddings and take the form of real-valued vectors in a multi-dimensional space. They allow computers to perform various downstream tasks such as translation, question answering, or classification.
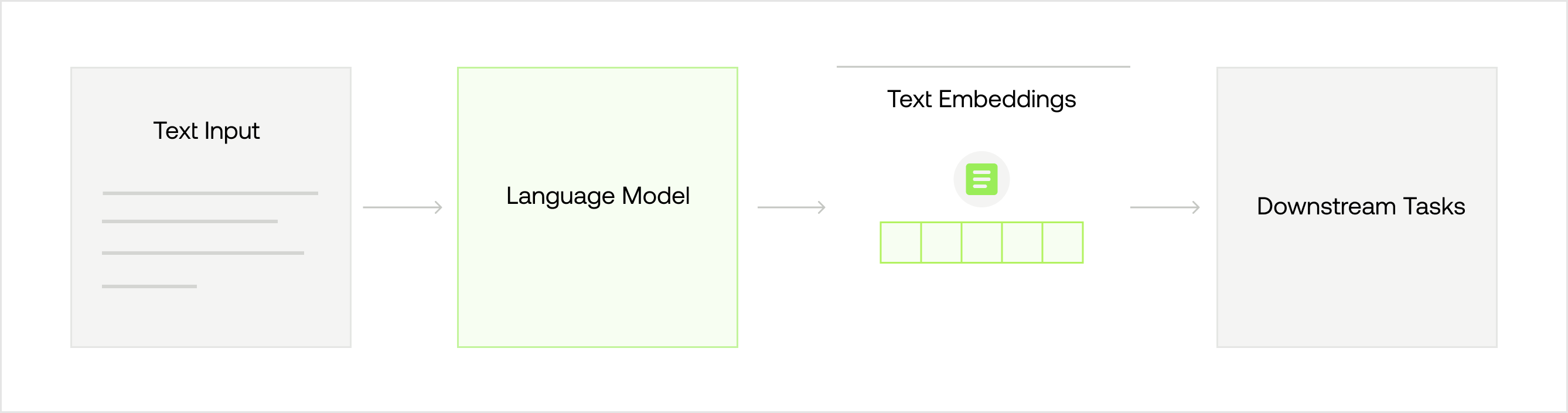
In contrast, when a multimodal language model processes a video, it generates a multimodal embedding that represents the overall context from all sources of information, such as images, sounds, speech, or text displayed on the screen, and how they relate to one another. By doing so, the model acquires a comprehensive understanding of the video. Once multimodal embeddings are created, they are used for various downstream tasks such as visual question answering, classification, or sentiment analysis.
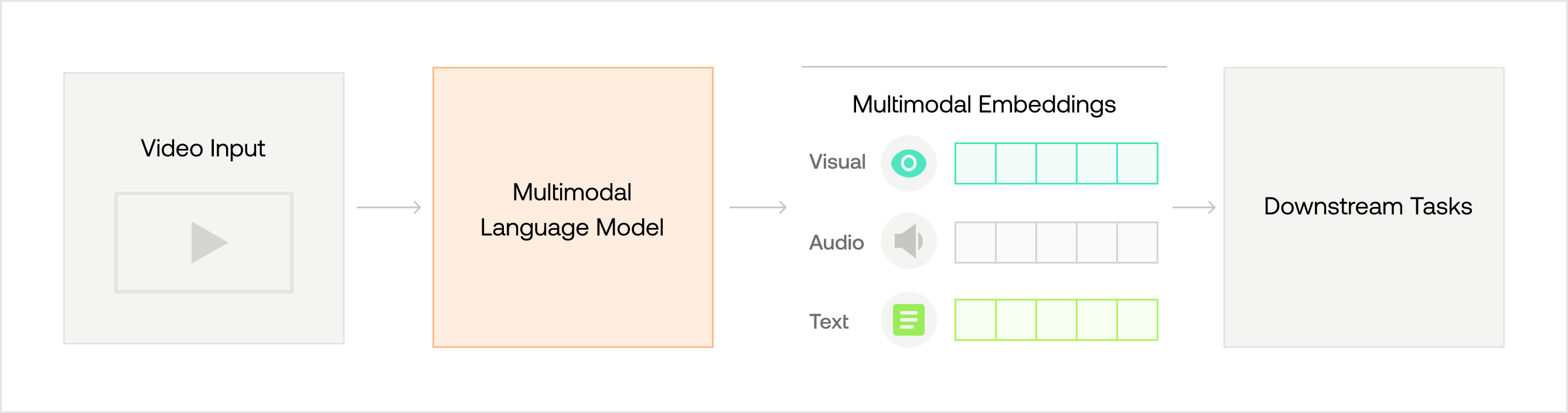
Twelve Labs has developed a multimodal video understanding technology that creates multimodal embeddings for your videos. These embeddings are highly efficient in terms of storage and computational requirements. They contain all the context of a video and enable fast and scalable task execution without storing the entire video.
The model has been trained on a vast amount of video data, and it can recognize entities, actions, patterns, movements, objects, scenes, and other elements present in videos. By integrating information from different modalities, the model can be used for several downstream tasks, such as search using natural language queries, perform zero-shot classification, and generate text summaries based on the video content.
Speech and Video Accelerate Multimodal AI
Multimodal AI is a research direction that focuses on understanding and leveraging multiple modalities to build more comprehensive and accurate AI models. Recent advancements in foundation models, such as large pre-trained language models, have enabled researchers to tackle more complex and sophisticated problems by combining modalities. These models are capable of multimodal representation learning for a wide range of modalities, including image, text, speech, and video. As a result, Multimodal AI is being used to tackle a wide range of tasks, from visual question-answering and text-to-image generation to video understanding and text-to-speech translation.
When combined, the technologies from ElevenLabs and Twelve Labs can elevate Multimodal AI to the mainstream, offering a more comprehensive understanding of human communication and interaction. By harnessing the power of both speech and video modalities, developers can create innovative applications that push the boundaries of what's possible in AI, ultimately transforming the way we interact with technology and the digital world.
AI Application Ideas for the Hackathon
During the 23Labs Hackathon, participants will have the opportunity to build innovative AI applications that leverage the APIs of both ElevenLabs and Twelve Labs. Here are some exciting ideas for inspiration:
- Video summarization with voiceover: Create a solution that automatically generates concise summaries of long videos (using Twelve Labs’ Generate API) and adds a voiceover (using ElevenLabs' AI-powered voice generator). This can be useful for news updates, educational videos, and conference presentations - saving time for viewers and enhancing accessibility.
- Smart video advertising: Develop an AI-based advertising platform that analyzes video ads content (using Twelve Labs' Classify API), gets common themes of high-ROI ads (using Twelve Labs’ Generate API), and generates targeted audio ads (by leveraging ElevenLabs' voice synthesis technology). This can help advertisers reach their target audience more effectively and improve the overall user experience.
- Multilingual video translation: Build a system that translates video content into multiple languages. Combine Twelve Labs' Generate API with ElevenLabs' multilingual audio support to provide synchronized translated subtitles and voice overs, enabling users to consume video content in their preferred language. This can be beneficial for international conferences, online courses, and global communication.
- Video content moderation with audio warnings: Create an AI-powered solution that automatically detects and filters inappropriate or sensitive content in videos. Use Twelve Labs' Classify API to identify inappropriate or offensive content in videos. Then use ElevenLabs' voice synthesis technology to provide audio warnings for such content. This can help ensure a safer and more inclusive viewing experience for users.
- Video language learning assistant: Develop an interactive language learning tool that uses video content to help users improve their language skills. Use Twelve Labs' Search API to identify and extract speech from videos. Then use ElevenLabs' multilingual audio support to generate pronunciation guides, vocabulary lessons, or listening exercises. This can make language learning more engaging and effective.
Resources for Hackathon Attendees
Participants can refer to the API documentation, tutorials, and blog posts from ElevenLabs and Twelve Labs below to prepare for the hackathon.
From ElevenLabs
From Twelve Labs
- Playground
- Playbook
- API Documentation: Quickstart, Video Understanding Engine, Frequently Asked Questions
- Tutorials + Blog Posts
- Discord Community
Conclusion
The 23Labs Hackathon offers a unique opportunity for developers, creators, and AI enthusiasts to dive into the world of Multimodal AI and create innovative solutions that push the boundaries of what's possible. By combining the expertise of Eleven Labs and Twelve Labs, participants will have access to state-of-the-art technologies in voice and video AI, enabling them to build applications that can truly transform the way we interact with digital content.
Don't miss your chance to be part of this groundbreaking event and explore the exciting opportunities that lie ahead in the field of Multimodal AI. Register now and join us at the 23Labs Hackathon to turn your ideas into reality!
Generation Examples
Comparison against existing models
Related articles

A beginner guide to video understanding for M&E with MASV and Twelve Labs


"Generate titles and hashtags" app can whip up a snazzy topic, a catchy title, and some trending hashtags for any video you fancy.


A Twelve Labs and MindsDB Tutorial

Our video-language foundation model, Pegasus-1. gets an upgrade!
