








This article is intended for researchers interested in exploring Multimodal AI topics and developers interested in building Multimodal AI applications. We hope to provide a better understanding of the field's current state and inspire new ideas and approaches for building more sophisticated and accurate models. As the field of Multimodal AI continues to evolve, there will be even more exciting applications and research opportunities in the future.
Introduction
The world surrounding us involves multiple modalities - we see objects, hear sounds, feel textures, smell odors, and so on. Generally, a modality refers to how something happens or is experienced. A research problem is therefore characterized as multimodal when it includes multiple modalities.
Multimodal AI is a rapidly evolving field that focuses on understanding and leveraging multiple modalities to build more comprehensive and accurate AI models. Recent advancements in foundation models, such as large pre-trained language models, have enabled researchers to tackle more complex and sophisticated problems by combining modalities. These models are capable of multimodal representation learning for a wide range of modalities, including image, text, speech, and video. As a result, Multimodal AI is being used to tackle a wide range of tasks, from visual question-answering and text-to-image generation to video understanding and robotics navigation.
In this article, we will be exploring the latest developments and trends in Multimodal AI. We will delve into the historical and modern applications of Multimodal AI. We will provide a comprehensive overview of the foundational principles of Multimodal AI, including modality heterogeneity, connections, and interactions. We will also discuss the core challenges researchers face when applying Multimodal AI to different applications, such as representation, reasoning, and generation.
1 - Multimodal AI Applications
1.1 - A Historical Perspective
One of the earliest examples of multimodal research is audio-visual speech recognition (AVSR). Early AVSR models were based on Hidden Markov Models (HMMs), which were popular in the speech community then. While AVSR research is not as common these days, it has seen renewed interest from the deep learning community.
Multimedia content indexing and retrieval is another important category of multimodal applications. Earlier approaches for indexing and searching multimedia videos were keyword-based, but new research problems emerged when directly searching the visual and multimodal content. This led to new research topics in multimedia content analysis, such as automatic shot-boundary detection and movie summarization, which were supported by the TrecVid initiative from the National Institute of Standards and Technologies.

A third category of applications was established in the early 2000s around the emerging field of multimodal interaction, with the goal of understanding human multimodal behaviors during social interactions. The AMI Meeting Corpus, containing over 100 hours of video recordings of meetings, was one of the first landmark datasets collected in this field. Another important dataset is the SEMAINE corpus, which allowed researchers to study interpersonal dynamics between speakers and listeners. This dataset formed the basis of the first audio-visual emotion challenge (AVEC) organized in 2011, which continued annually afterward with later instantiations, including healthcare applications such as automatic assessment of depression and anxiety.
After that, another category of multimodal applications emerged with an emphasis on language and vision: media description. Image captioning is one of the most representative applications, where the task is to generate a text description of the input image. The main challenge in a media description system is evaluation: how to evaluate the quality of the predicted descriptions. The task of visual question-answering (VQA) was proposed to address some of the evaluation challenges by answering specific questions about the image.
1.2 - A Modern Perspective
Multimodal AI is being used to tackle a wide range of applications across various industries. One exciting application is in autonomous vehicles, where multimodal AI can help improve safety and navigation by integrating multiple sensor modalities, such as cameras, lidars, and radar. Another area where multimodal AI is making advances is in healthcare, where it can assist in the diagnosis and treatment of diseases by analyzing medical images, text data, and patient records. Combining modalities can provide a more comprehensive and accurate assessment of patient health.

Multimodal AI is also used in the entertainment industry to create more immersive and interactive user experiences. For example, virtual and augmented reality technologies rely heavily on multimodal AI to create seamless interactions between users and their digital environments. Additionally, multimodal AI is used to generate more engaging and personalized content, such as custom recommendations and dynamically generated video content. As researchers continue to explore the potential of multimodal AI, we will likely see even more creative and impactful applications emerge.
2 - Foundational Principles In Multimodal Research
Academically speaking, Multimodal AI is a computational field focusing on understanding and leveraging multiple modalities. Modalities can range from raw, sensor-detected data, such as speech recordings or images, to abstract concepts like sentiment intensity and object categories. According to an in-depth survey by Carnegie Mellon researchers earlier this year, three key principles of modality heterogeneity, connections, and interactions have driven subsequent technical innovations in Multimodal AI.
2.1 - Heterogeneity
One of the key insights of multimodal AI is that modalities are heterogeneous, meaning they often exhibit diverse qualities, structures, and representations. For example, an image and a speech recording of the same event may convey different information, requiring unique processing and analysis.

More specifically, there are six dimensions of heterogeneity: element representation, distribution, structure, information, noise, and relevance. These dimensions measure differences in the sample space, frequencies and likelihoods of elements, underlying structure, information content, noise distributions, and task/context relevance.
2.2 - Connections
Modalities often share complementary information and can work together to create new insights. Researchers in multimodal AI study these connections through statistical analysis of associations and semantic correspondence.

Bottom-up reasoning involves statistical association (where one variable's values relate to another's values) and statistical dependence (which requires understanding the exact type of dependency between two elements). This is important for modeling joint distributions across modalities.
Top-down reasoning involves semantic correspondence (which identifies which elements in one modality have the same meaning as elements in another modality) and semantic relations (which include an attribute that describes the nature of the relationship between two modality elements, such as semantic, logical, causal, or functional). Identifying semantically related connections is important for higher-order reasoning.
2.3 - Interactions
Finally, modalities interact in different ways when they are integrated into a task. This interaction can take many forms, such as how an image and a speech recording might be combined to recognize an object or person. Understanding these interactions is crucial for building effective multimodal AI models.

In particular, there are three dimensions of interactions: interaction information, interaction mechanics, and interaction response. Interaction information investigates the type of connected information involved in an interaction. On the other hand, interaction mechanics are the functional operators involved when integrating modality elements for task inference. Finally, interaction response studies how the inferred response changes in the presence of multiple modalities.
2.4 - Core Research Challenges
Building on the three core principles mentioned above, the authors provide six core challenges in multimodal research: representation, alignment, reasoning, generation, transference, and quantification.
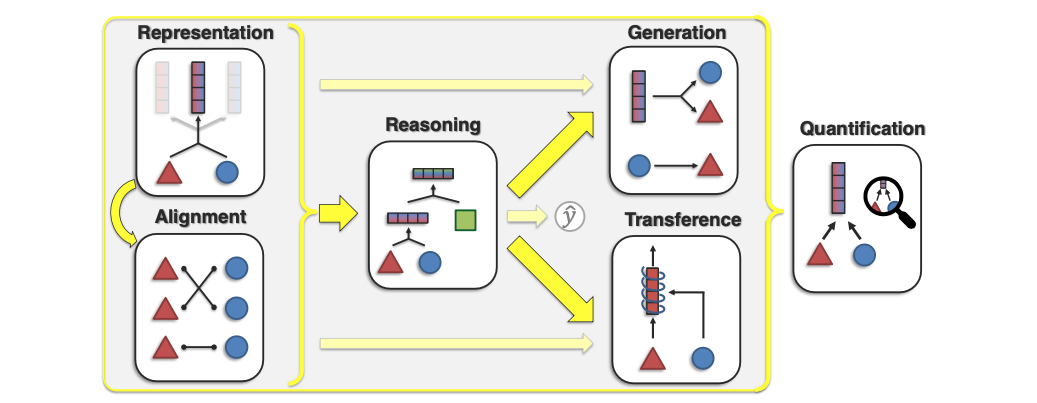
These challenges grabble with answering the following questions:
- How can we learn representations that reflect heterogeneity and interconnections between modalities? (Representation)
- How can we identify cross-modal connections and interactions between modalities? (Alignment)
- How can we compose knowledge that exploits the problem structure for a specific task? (Reasoning)
- How can we learn a generative process to produce raw modalities that reflect cross-modal interactions, structure, and coherence? (Generation)
- How can we transfer knowledge between modalities? (Transference)
- How can we conduct empirical and theoretical studies of multimodal learning? (Quantification)
Given these challenges, let’s double-click on the three major ones: Representation, Reasoning, and Generation.
3 - Multimodal Representation
Significant advancements have been made in representing vision and language, but it is still insufficient to fully represent all human concepts using only one modality. For instance, the idea of a "beautiful picture" is grounded in visual representation, making it hard to describe through natural language or other non-visual ways. That is why learning joint embeddings that use multiple modalities to represent such concepts is crucial.
3.1 - Multimodal Pre-training
The primary goal of multimodal representation learning is to narrow the distribution gap in a joint semantic subspace while maintaining modality-specific semantics. Recent research directions in multimodal representation have focused on multimodal pre-training. Given the tremendous capabilities of large pre-trained language models, there have been a lot of attempts at foundation models learned via multimodal pre-training. We have covered this trend of foundation models going multimodal in depth in this article.
These models are capable of multimodal representation learning for image + text (CLIP, ALIGN, BLIP, BLIP-2, FLAVA), image + text + speech (data2vec), video + text (UniVL), video + image + text (MaMMUT), video + audio + text (Florence, VATT), and video + image + audio (PolyViT).
Gato by DeepMind and ImageBind by Meta are two multimodal foundation models that can accomplish even a wider range of tasks.

Gato is a generalist agent that can perform over 600 tasks, including conversing, captioning photographs, stacking blocks with a real robot arm, outperforming humans at Atari games, navigating in simulated 3D environments, and following instructions. The guiding design principle of Gato is to pre-train on the widest variety of relevant data possible, including diverse modalities such as images, text, proprioception, joint torques, button presses, and other discrete and continuous observations and actions.

On the other hand, ImageBind is a new model that can bind information from six modalities, including text, image/video, audio, depth (3D), thermal (infrared radiation), and inertial measurement units (IMU). Although it is only a research project at this point, it points to a future of multimodal AI systems that can create immersive, multi-sensory experiences (such as searching for pictures, videos, audio files, or text messages using a combination of text, audio, and image).
3.2 - Limitations in Pre-training
Pre-trained models have emerged as powerful tools for solving tasks that require cross-modal knowledge. However, their performance can sometimes falter when applied to modality-specific downstream tasks. As such, the use of pre-trained models may not always be the most effective strategy. More specifically, here are the major limitations:
Scaling Laws and Bottlenecks
There may be some future bottlenecks in computational resources and instability in the pre-training process, especially when extending pre-training to the multimodal setting. Papers that study scaling laws, such as those for Generative Mixed-Modal Language Models and Autoregressive Generative Modeling, will become increasingly important in the years to come.
Knowledge Transfer
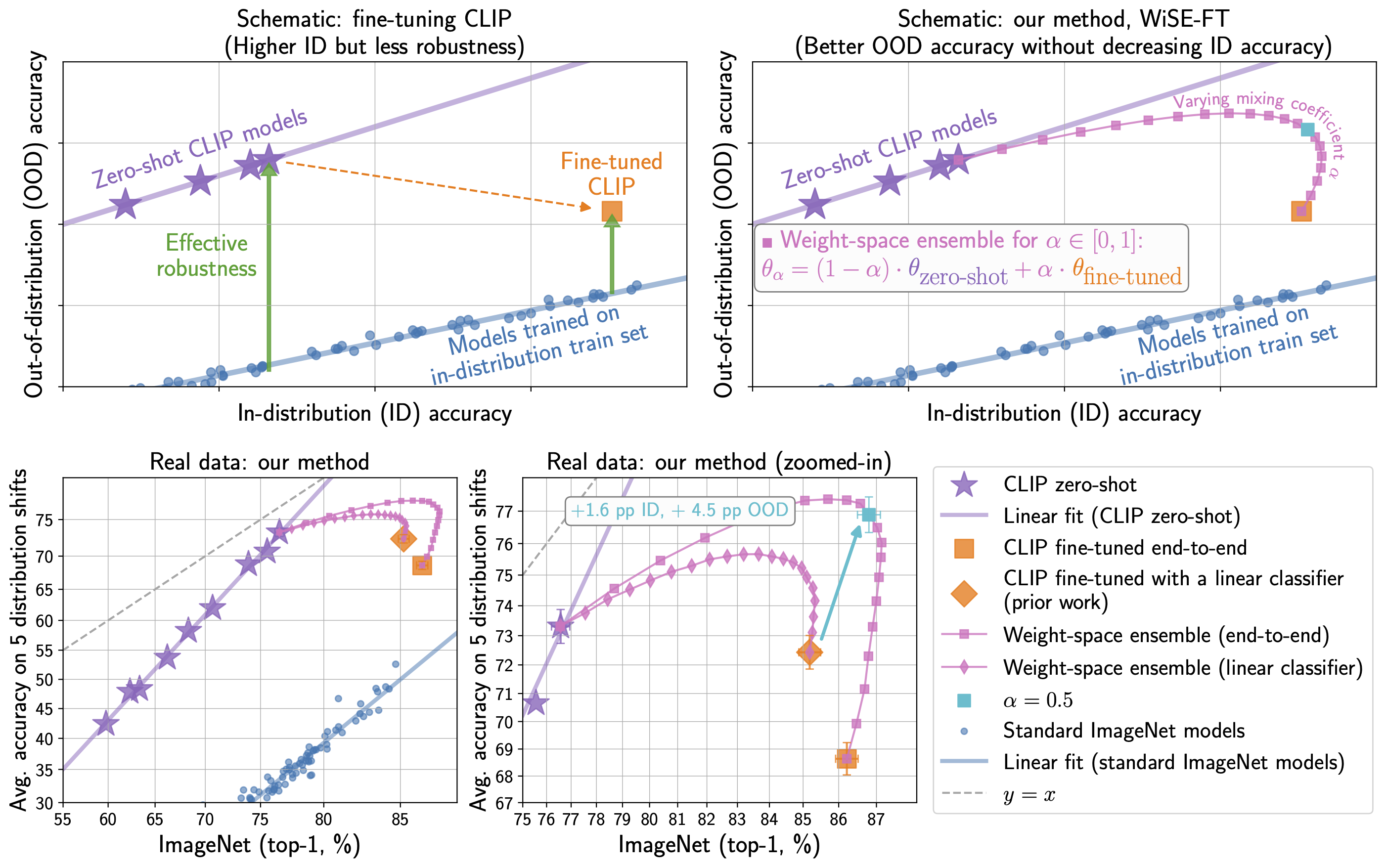
Fine-tuning a pre-trained model on another task may adversely affect its robustness and performance (as observed in the WiSE-FT paper). In particular, fine-tuning CLIP on ImageNet could reduce the model’s robustness to distribution shifts. Not fine-tuning CLIP and applying it directly to downstream tasks has the potential to yield better performance. These findings suggest that knowledge transfer, especially as it relates to pre-training and robustness, is a challenging task worthy of future research investment.
Architecture Restriction
Generally, multimodal pre-trained models use Transformers as the model backbone. However, Transformers might sometimes not work well on all modalities. For example, Vision Transformer requires additional tuning tricks to obtain higher performance. This reveals that Transformers might not be suitable for some modalities. It is possible that modality-specific architectures may be more useful in certain contexts; formalizing when and where these contexts occur is an important future research direction.
Domain-Specific and High-Stakes Problems
Pre-trained models have demonstrated remarkable performance on general tasks and common research areas such as vision and language. However, they may falter when adapted to downstream tasks requiring highly specific domain knowledge. In addition, fields such as healthcare will exhibit low error tolerance for multimodal models deployed in real-world settings. In such scenarios, relying solely on systems built from pre-trained models will pose risks since these models (currently) are black boxes with no formalized approach for controlling their real-time behavior predictably.
Computational Requirements
Large pre-trained models have computing restrictions due to their size and complexity, which can make training and inference prohibitively expensive. This has prompted researchers to explore efficient model architectures and optimization techniques, such as distillation, pruning, and quantization, to reduce the computational cost of large pre-trained models.
Robustness
Despite their impressive performance on many tasks, large pre-trained models can be vulnerable to adversarial attacks. This vulnerability has important implications for the deployment of large pre-trained models in high-stakes applications.
3.3 - Cross-Modal Interactions and Multimodality
Multimodal pre-training aims to capture connections and interactions between different types of data. One way to do this is through Transformers, which standardizes how information is represented (by converting every type of data into a sequence of tokens).
Parameters in large models can limit the types of interactions and cross-modal information that the model can capture. The goal is for models to learn how different modalities align with each other during pre-training. However, other approaches can achieve this by operating on top of frozen models, such as in FROMAGe (Frozen Retrieval Over Multimodal Data for Autoregressive Generation).

Multimodal pre-training tasks can help models learn cross-modal relationships. For example, given some input text, a model could be trained to predict which audio token comes next. This would align sequences of text with audio. Another example is word-region alignment, which helps the model learn how textual and visual data are semantically related.
In a multimodal model, there may be subnetworks that represent individual modalities (as observed in this paper on parameter-efficient multimodal Transformers for video representation learning). This area of research could be explored further to understand cross-modal connections better.
3.4 - Future Direction
Given the surge of Large Language Models (LLMs) development recently, it is possible that natural language could be the best modality to guide multimodal pre-training. These LLMs are strong learners in various diverse downstream task domains, many of which are multimodal. Examples can be found in “Conditional Prompt Learning for Vision-Language Models” and “Multimodal Transformer for Unaligned Multimodal Language Sequences.“

Language is naturally sequential, making it useful in integrating other modalities. An example is the family of Socratic Models, which uses language to guide the zero-shot composition of foundation models for multimodal tasks. Language can also be used in pre-training to align and fuse information across modalities.
Finally, natural language is what humans use to describe objects and communicate. Using text as a decoder for large pre-trained models can help humans interpret and probe what the model is learning during multimodal pre-training. Given the popularity of OpenAI’s ChatGPT, there have been vision-language models like Visual ChatGPT and Multimodal-GPT that can conduct multi-round dialogue with humans.
4 - Multimodal Reasoning
One way to understand reasoning is by following a logical chain to reach a conclusion (Chain-of-Thought Reasoning). Reasoning in models encapsulates the model's ability to show us how it came to its answer. There are different ways to represent the model's reasoning process, and it is important to measure performance over different components and lines of reasoning, not only accuracy in the end task. Other than the standard Chain of Thought, future research could look at more structured representations, such as a Tree of Thoughts, in order to make evaluation easier.
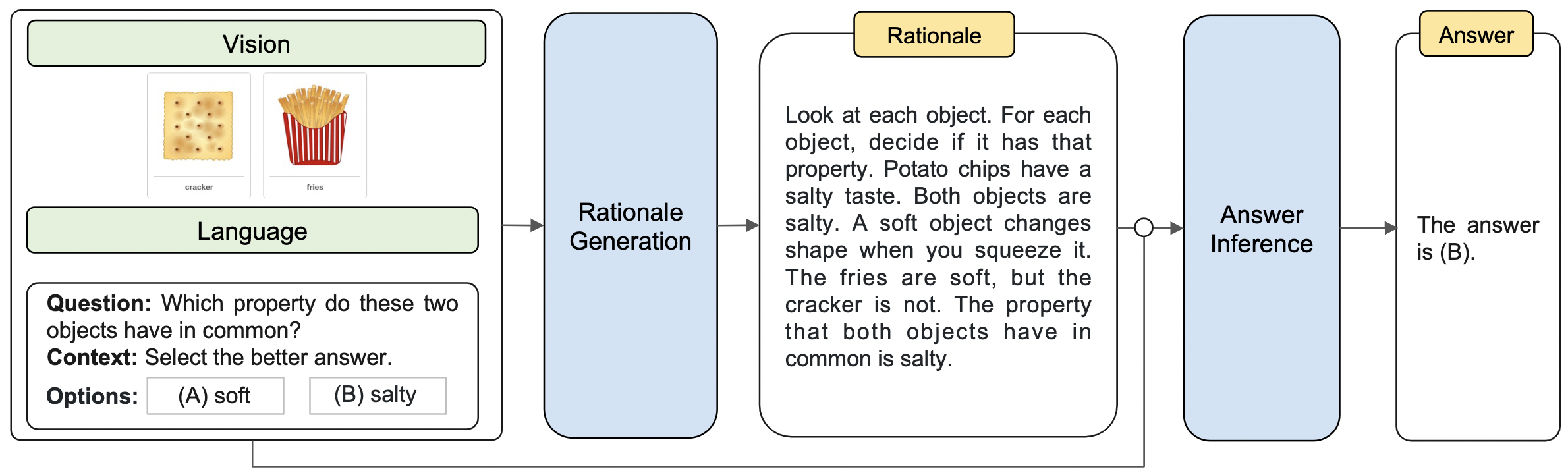
Another approach is to create a formal taxonomy for reasoning, which aims to understand and reason with the available information. The taxonomy can be classified along different dimensions, such as single-step vs. multi-step, deterministic vs probabilistic, and temporal-based vs non-temporal. Ideally, it should contribute to different sub-challenges of reasoning, such as ensuring consistent reasoning and sufficient evidence.
4.1 - How Do Pre-Trained Models Reason?
Large-scale pre-trained models are powerful at learning representations without explicitly modeling reasoning, but this makes them less interpretable compared to models that do include symbolic reasoning. Pre-trained models may also be less robust because they can pick up on biases from only one type of input.
Since pre-trained models are like black boxes, it is natural to wonder how they reason. Here are some methods to uncover their reasoning abilities:
Latent space visualization (CLIP): In a shared space for language and vision, we can see if visual objects and text phrases are close together.
Attention head inspection (VisualBERT, Multi-Head Attention with Diversity): For Transformer-based models, we can look at the attention scores in each head between a pre-selected keyword in text and a pre-selected object patch in an image.

Stress-testing (SMIL): We can change the input to the model to see how it affects the output. We can also remove one type of input during training to see if the model can still reason. Finally, we can add fake inputs and see if the model's performance changes.
Perception system degradation (Neuro-Symbolic Visual Reasoning): We can intentionally give the model less information to see if it can still reason well.
Reasoning paths (Chain-of-Thought Prompting, Recursive Grounding Tree, Heterogeneous Graph Learning): Can we create a short sentence series that mimics how a person would reason when answering a question? Or can we make a graph or tree to understand the reasoning process?
4.2 - Challenges in Multimodal Reasoning
There are a couple of key challenges in multimodal reasoning:
Model and Training Design
LLMs perform well in NLP, but no one knows the best architecture for multimodal learning yet. Reinforcement learning (RL) is one training paradigm to consider. Its advantage is an exploration phase where the model learns to come to a solution without explicit supervision but only defined rewards. This could allow for more natural and guaranteed steps of reasoning than with supervision.
Evaluation
It is difficult to determine which modalities are necessary for reasoning. The reasoning path may not be naturally shown for some modalities. Additionally, it is not clear how to evaluate a model's reasoning process. Model-free scores like BLEU may unfairly penalize correct processes. Model-based scores may introduce an extra layer of bias.
Dataset
Creating multimodal reasoning datasets at scale, especially with N-way-aligned data, is challenging. One approach to address this is the family of Socratic Models. These models efficiently combine pairwise multimodal models to perform reasoning on many tasks. They use the language model as a semantic "core" to link outputs from different pre-trained models through chain prompting.
This method is easy to use and does not require extra training. However, getting a reward for an unobserved state during simulation/exploration can be costly and may require human annotation. A future research direction is to combine RL with pre-training. Pre-training can get the model to a more learned state, and sparse RL rewards may be enough to learn a strong policy.
4.3 - How Are Reasoning Models Useful to Us?
Currently, the search paradigm we use relies on entering queries in particular formats to go through articles that provide an answer and rationale. ChatGPT-style conversational reasoning allows for specific, unique questions to be asked and answered with an explanation. Getting curated, logical rationales in reasoning questions is crucial. However, ChatGPT can only take text input and provide text answers and rationales in the context of multimodal question answering (especially commonsense reasoning). A multimodal rationale, such as a visual rationale like Grad-CAM, could be more useful for complex scenes.

Retrieving evidence in reasoning is also important for verifying the reasoning model and exploring further. For example, external knowledge graphs may provide useful support. A pre-trained model could generate an answer and query a multimodal knowledge graph to provide evidence, similar to how humans use Google for proof and sources to confirm. For instance, newer search engines like BingChat, Perplexity, and YouChat are making efforts to add references to generations for conversational search.
5 - Multimodal Generation
Multimodal generation involves learning a generative process to produce raw modalities that reflect cross-modal interactions, structure, and coherence. This particular domain has been very hot recently, given the rise of Generative AI thanks to products like ChatGPT and Midjourney.
5.1 - Multimodal Generation Tasks
At a high level, multimodal generation can be categorized into three broad categories: summarization, translation, and creation.
Summarization
This task is about making a short version of some information that only includes the most important parts. For example, if there is a news video, the short version would summarize what was said in the video. The summary can also include some pictures from the video.
There are two main ways of making the summary: extractive and abstractive. Extractive approaches (like this one, this one, and this one) remove some words or phrases from the original information to create the summary. Video summarization is a type of extractive summary that encapsulates the most important parts of a video.
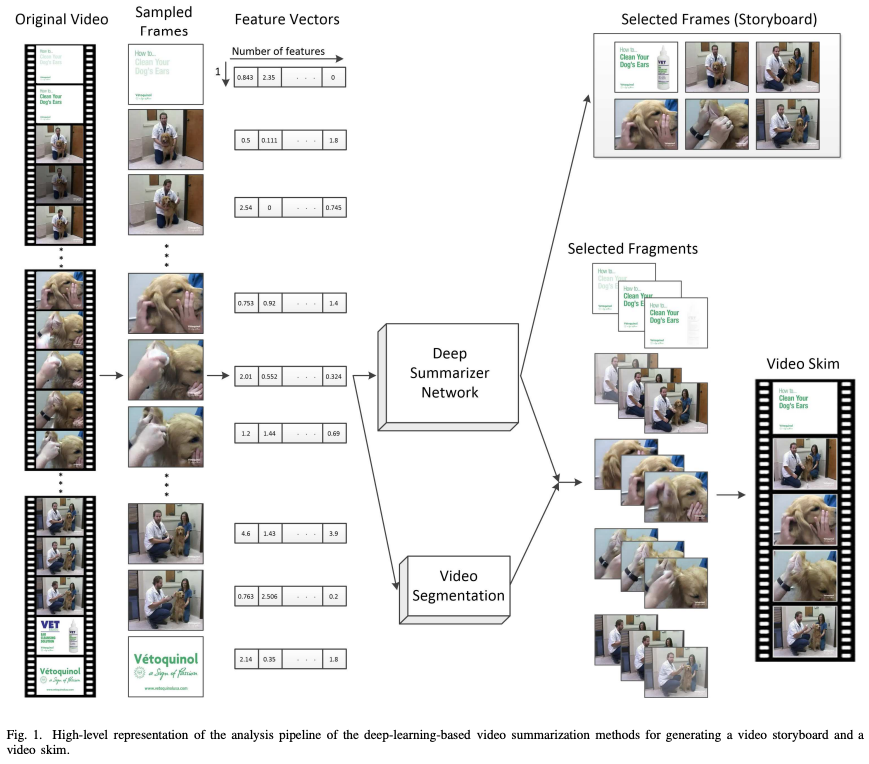
Abstractive approaches (like this one and this one) use a generative model to create a summary at multiple levels of granularity. Most approaches only generate a textual summary, but several directions have also explored generating summarized images to supplement the generated textual summary.
Translation
This task involves translating between two different modalities while keeping semantic connections and information content the same. One example is generating images from textual descriptions, like DALL-E 2. Multimodal translation comes with new challenges, like generating and evaluating high-dimensional structured data.
Recent approaches can be divided into two groups: exemplar-based (like this system), which only uses training examples to translate between modalities but guarantee fidelity, and generative models (like Frozen and TReCS), which can translate to new examples but face challenges in quality, diversity, and evaluation.

Despite these challenges, recent improvements in large-scale translation models have created impressive quality of generated content for tasks like text-to-image (Latent Diffusion), text-to-video (Make-A-Video), audio-to-image (You Said That?), text-to-speech (FastSpeech), speech-to-gesture (Mix-StAGE), speaker-to-listener (Learning2Listen), language-to-pose (Language2Pose), and speech and music generation (Parallel WaveNet).
Creation
This task involves creating novel high-dimensional data that can include text, images, audio, video, and other modalities. This is done using small initial examples or latent conditional variables. It is very difficult to do this conditional decoding process because it needs to be:
- Conditional: preserve semantically meaningful mappings from the initial seed to a series of long-range parallel modalities,
- Synchronized: semantically coherent across modalities,
- Stochastic: capture many possible future generations given a particular state, and
- Auto-regressive across possibly long ranges.

Many modalities have been considered as targets for creation. Language generation (GPT-2) has been explored for a long time, and recent work has explored high-resolution speech and sound generation using neural networks (Parallel WaveNet). Photorealistic image generation (StyleGAN2) has also recently become possible due to advances in large-scale generative modeling. Furthermore, there have been several attempts at generating abstract scenes (Text2Scene), computer graphics (Neural Radiance Fields), and talking heads (Audio-Visual Coherence Learning). While there has been some progress toward video generation, a complete synchronized generation of realistic video, text, and audio remains challenging.
5.2 - Challenges in Multimodal Generation
There are also several core challenges in multimodal generation: controllability, compositionality, synchronization, and capturing long-tail phenomena.
Controllability
Controllability is important for multimodal generation models because users may want to create photo-realistic images in a specific style. To achieve controllability, different approaches can be taken, such as guiding the decoding process through latent variable models or using different sampling schemes.
Compositionality
Multimodal generation models should be able to understand complex inputs and generate appropriate outputs across different modes. However, the recent Winoground challenge has shown that many language-visual models fail to interpret non-standard language and images correctly. Strong unimodal language models (like GPT-3) have made significant progress in understanding compositional language, but there is still a gap in the multimodal setting. Closing this gap presents an interesting research challenge.

Synchronization
Synchronization is another important concern when generating multiple modalities. It is critical to synchronize modalities appropriately for the generation to be semantically coherent. For example, generating dialogue in a video involves synchronizing a unique voice with a person speaking in the clip. The voices would also need to remain consistent across utterances. Evaluating synchronization is a challenge because developing automated evaluation is difficult. Human evaluation is a possible alternative but has drawbacks, such as a lack of reproducibility.
Capturing Long-Tail Phenomenon
Effective multimodal generation models should capture long-tail phenomena that may not be well-represented in the training dataset. This challenge is related to the mode collapse problem observed with generative models such as GANs. It is important to generate diverse images to handle this challenge while remaining faithful to the text that prompts the generation.
Depending on the user's intent, language descriptions can be intentionally vague or very specific. However, utilizing complex, highly specific language descriptions for generation can increase the task's difficulty. An interesting research direction is exploring whether alternative representations (e.g., symbolic) could be developed to guide generative models with greater control.
5.3 - Ethical Issues
Multimodal generation raises a wide array of real-world ethical issues.
Job Displacement
Generative models are getting better at doing things that used to be done by people. This might mean that the day-to-day tasks of some jobs will be reduced. However, it might also mean that people will be able to spend more time doing creative and interesting work while the machines do the tedious and repetitive tasks. We need to be careful and think about the best way to use generative models in the workplace.
We should find a balance between letting machines do some tasks and having people do others. Unfortunately, the laws and rules about AI have not kept up with technological changes. We need to update the rules to avoid problems with job loss and other issues.
Plagiarism and Privacy
Generative models are capable of producing creative content. However, it is uncertain if they can generate truly original ideas without copying and combining existing human sources. Copyright issues arise because there is no guaranteed method to identify the sources used in the generation process. Attribution models (like GAN Fingerprints) can possibly address this by identifying the sources used by generative models and providing digital signatures for authors to safeguard their intellectual property.

Generative models may also be trained on personal data, presenting privacy concerns. Therefore, it is important to develop models that can detect personal information in the training data and create strategies to measure and reduce the privacy leakage of generative models.
Human Creativity
Generative models are not meant to replace human creativity but rather to assist and improve it. Humans still have the final say in creating and judging creative content. However, more research is needed to address ethical concerns about generative models and human creativity and to study the impact of these models and the role of humans in the creative process.
Deepfakes, Cyberbullying, and Fake News
The ethical concerns around generated images, audio, and video are important to consider. Generative Adversarial Networks (GANs) are an example of adversarial models that differentiate between machine-generated and human-generated content. However, the effectiveness of these models depends on the quality of the discriminator used.
Another concern with deepfakes is the potential generation of fake sensitive content, such as nudity. To ensure the public's safety, it is necessary to prevent the model from generating such content during pre-training and develop models that can distinguish real recordings from Deepfakes.
6 - The Future of Multimodal Foundation Models
Recent advances in foundation models have shown remarkable results in tasks such as video generation, text summarization, information extraction, and text-image captioning. Moreover, it is becoming increasingly easier to interact with these models through prompts or chat.
We believe that the next generation of large foundation models will undoubtedly leverage more multi-modal data, especially audio, text, and videos from YouTube. YouTube remains an untapped source of nearly infinite unconstrained data that provides paired multi-modal data for free. Furthermore, future foundation models will embrace continual learning to adapt based on user queries, feedback, and new information created on the internet. This will ensure that foundation models continue to update as new information is created.
At Twelve Labs, we are developing foundation models for multimodal video understanding. Our goal is to help developers build programs that can see, listen, and understand the world as we do with the most advanced video-understanding infrastructure. If you would like to learn more, please sign up at https://playground.twelvelabs.io/ and join our Multimodal Minds Discord community to chat about all things Multimodal AI!
Generation Examples
Comparison against existing models
Related articles

A beginner guide to video understanding for M&E with MASV and Twelve Labs


"Generate titles and hashtags" app can whip up a snazzy topic, a catchy title, and some trending hashtags for any video you fancy.


Our video-language foundation model, Pegasus-1. gets an upgrade!


This blog post introduces Marengo-2.6, a new state-of-the-art multimodal embedding model capable of performing any-to-any search tasks.
