








In today's digital age, videos have become an integral part of our lives, capturing our attention and imagination like never before. With the explosive growth of online video content, the need to understand and analyze videos has become increasingly crucial. Enter video understanding, a fascinating field that harnesses the power of artificial intelligence and machine learning to decipher the rich visual information embedded in videos.
In a previous article, we looked at the evolution of video understanding from an academic perspective. In this article, we will embark on a captivating tour of video understanding and explore its diverse range of use cases.
1 - From Language Understanding to Video Understanding
The evolution of machine learning models for natural language understanding has seen significant advancements in recent years thanks to the introduction of the Transformer architecture. From the original architecture, different models emerged, such as BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer).

BERT architecture focuses on embedding use cases that generate contextualized word embeddings from large-scale unsupervised data. These embeddings can be used for various NLP tasks, such as text classification, sentiment analysis, and named entity recognition. BERT's bidirectional nature allows it to capture context from a given word's left and right sides, resulting in more accurate and meaningful embeddings. Real-world applications of BERT include improving search engine results, enhancing chatbot understanding, and optimizing content recommendation systems.
On the other hand, GPT architecture powers generative use cases, which involve generating human-like text based on a given input. GPT models, such as GPT-3, have been trained on vast amounts of data, enabling them to generate coherent and contextually relevant text. These models can be used for various tasks, such as text summarization, question answering, and generating visuals. Real-world applications of GPT include customer service support, content generation, and language translation.
The evolution of models for video understanding has followed a similar trajectory to that of language understanding. Video foundation models have emerged to power use cases that leverage video embeddings. These models learn from video data using principles similar to those employed by foundation models in the language domain, such as BERT and GPT. They can generate embeddings for various video understanding tasks, such as video search, video classification, action recognition, and temporal localization.

In addition to video foundation models, there has been a rise in video-language models that power use cases involving video-to-text generation. Like their language counterparts, these models are trained on large paired datasets of videos and text descriptions. Video-to-text generation tasks include video captioning and video question answering, which require the model to produce a suitable text response based on multimodal inputs, such as video plus text, speech, or audio. The development of video-language models has been influenced by the success of hybrid vision-language models, which combine the power of computer vision and natural language processing to solve complex problems.
2 - Video Foundation Models
2.1 - The Magic of Video Embeddings
Video embeddings refer to the representation of videos in a lower-dimensional vector space, where each video is represented as a numerical vector. These embeddings capture the semantic meaning and visual features of the videos, allowing foundation models to understand the content of videos.

The popularity of video embeddings can be attributed to the multimodal evolution of vector embeddings. Traditionally, vector embeddings were solely focused on text, image, and audio data. However, with the rise of multimedia content and the versatility of the Transformer architecture, there has been a shift towards developing embeddings that can capture visual, textual, and audible information in a shared latent space.
Multimodal embeddings combine different modalities within videos to create a comprehensive representation. These embeddings provide a more holistic understanding of the video content by incorporating visual, textual, and audible cues. As a result, they enable a wide range of applications in various domains, such as video search, classification, and clustering.
2.2 - Video Search

One of the most captivating aspects of video understanding is its ability to make videos searchable and classify them based on their content. Imagine being able to find a particular video in a vast collection simply by describing its visual elements or keywords. Video search is the task of analyzing the semantic information of videos, thereby enabling efficient and accurate retrieval of specific video content. It plays a crucial role in helping users navigate through vast video libraries and discover the videos they are looking for without having to watch them.
Challenges
Developing video search solutions for real-world applications presents several challenges. First, videos often combine visual and auditory information, making the search process more complex. Additionally, there is an inherent temporal dimension inside videos. The evolution of the relationship between the visual and audio elements over time is what produces the rich context that is foundational to what video is.
In video understanding, different modalities may carry different meanings, and the model needs to interpret the overall meaning by considering the nuances and contexts of each modality. For example, if someone is laughing but looks sad or says something negative, the model needs to accurately determine the person's overall emotion. This requires the model to capture and analyze the subtle cues and interactions between different modalities, taking into account the visual expressions, body language, spoken words, and the overall context of the video. Achieving this level of understanding is a complex task that involves advanced multimodal foundation models and the integration of various data sources to capture the rich and multidimensional nature of videos.
Secondly, understanding user intent and providing relevant search results is another challenge in video search. Interpreting user queries, preferences, and context to deliver accurate and personalized video search results requires advanced recommendation and relevance ranking algorithms. This task becomes even more challenging in different video domains, such as user-generated content, gaming, and sports, where each domain has its own specific vocabulary, context, and user behaviors. Adapting the algorithms accordingly is necessary to ensure accurate and up-to-date search results that meet user expectations, especially considering the dynamic nature of these domains with constantly evolving trends and preferences.
Finally, real-world video search applications often deal with large-scale video libraries, which require efficient indexing and retrieval mechanisms. Developing scalable algorithms and infrastructure to handle the volume of video data and the required latency to retrieve relevant information is crucial for effective video search.
Use Cases
Video search engines use various techniques, such as content-based analysis, object detection, and text recognition, to index and search for videos based on their content. By eliminating the need to watch entire videos, video search saves time and improves efficiency in finding specific information or moments within videos.
Real-world examples of video search technologies include:
- YouTube: As one of the largest video-sharing platforms, YouTube offers a powerful video search engine. Users can search for videos based on keywords, titles, or specific categories.
- Specialized archival sites: Dedicated video search engines focus on specific types of videos, such as NASA's archival site. These platforms allow users to search for videos related to specific topics or events.
- Enterprise video search tools: Organizations often use video search tools to index and search their internal video libraries. These tools enable employees to find specific videos or moments within videos for various purposes, such as training, knowledge sharing, and research.
Traditional video search engines mentioned above have limitations in their approach to video search. These engines primarily rely on keyword matching and metadata analysis to index and retrieve videos. While these techniques can be effective to some extent, they do not take advantage of multimodal techniques that can provide a more comprehensive understanding of video content. By solely focusing on keywords and metadata, these search engines may miss important visual and auditory cues within the videos that could greatly enhance the search experience.
Twelve Labs’ Video Search API
Twelve Labs Video Understanding platform provides a Video Search solution that moves beyond the limitations of relying solely on individual types of data like keywords, metadata, or transcriptions. By simultaneously integrating all available forms of information, including images, sounds, spoken words, and on-screen text, our solution captures the complex relationships among these elements for a more human-like interpretation. It is designed to detect finer details frequently overlooked by unimodal methods, achieving a deeper understanding of video scenes beyond basic object identification. Additionally, it supports natural language queries, making interactions as intuitive as your daily conversations.
For more information about our Search capability, check out this 2-part tutorial (Part 1 and Part 2) and this page on using Search programmatically.
2.3 - Video Classification
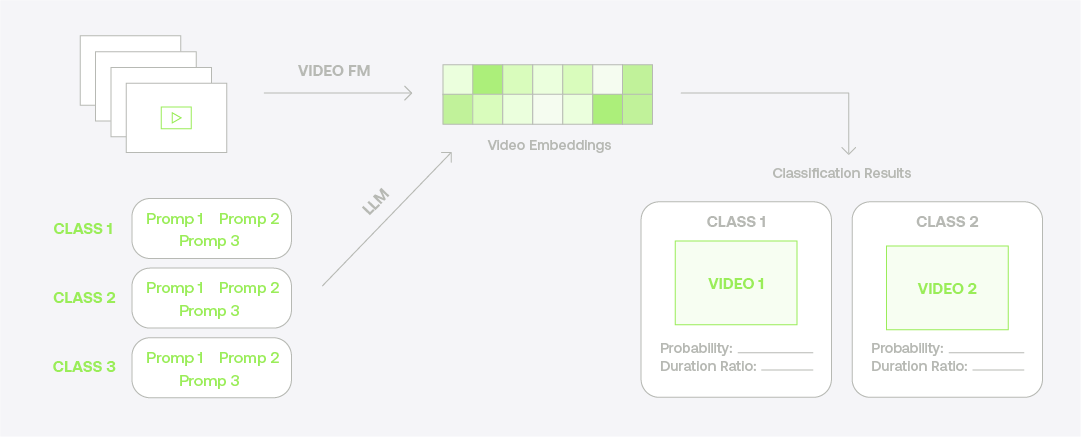
Video classification takes video understanding further by automatically categorizing videos into predefined classes or topics. The video foundation model can classify videos into sports, news, entertainment, or documentaries by analyzing the semantic features, objects, and actions within a video. This not only benefits content creators and video platforms but also enhances user experiences by providing personalized recommendations based on their interests and preferences.
Challenges
Building video classification models for real-world applications comes with several challenges. Firstly, creating labeled datasets for video classification can be labor-intensive and time-consuming. Videos can contain various visual elements, such as objects, scenes, and actions, which must be accurately labeled for classification tasks. This requires human annotators to carefully watch and analyze the videos, frame by frame, to assign the appropriate labels. Unlike images, videos have a temporal dimension, and the context of a video can change over time. Annotators must consider the entire video sequence to assign the correct label, which adds complexity and time to the labeling process.

Another challenge with video classification is that current technology relies on a fixed taxonomy of classes, which is often difficult to adapt to specific use cases and domains. For example, content creators on platforms like YouTube may want to classify their videos into more refined categories that better represent their content. However, the default set of 15 categories provided by YouTube may not be sufficient to accurately classify the diverse range of videos being created. This limitation highlights the need for more flexible and customizable classification systems that can better cater to the unique requirements of different industries and content creators.
Use Cases
Video classification has various applications in different industries.
- Surveillance and Security: Video classification is employed in surveillance systems to identify and classify specific actions or behaviors captured in video footage. It aids in detecting anomalies, recognizing suspicious activities, and enhancing security measures.
- Content Moderation: Video classification can be utilized in content moderation to automatically identify and categorize videos based on their content. This helps platforms and organizations enforce community guidelines, detect inappropriate or harmful content, and ensure a safe and positive user experience.
- Sports Analysis: Video classification is used in sports for player performance analysis. It helps identify and categorize players' different actions and movements during games, enabling coaches and analysts to gain insights for training and strategy development.
- Automated Video Editing: Video classification can be utilized for automated video editing, where the system automatically identifies and segments different scenes or events within a video. This simplifies the editing process and saves time for content creators.
- Contextual Advertising: Video classification can play a crucial role in contextual advertising by analyzing the content of videos and matching them with relevant advertisements. This enables advertisers to target their audience more effectively and deliver personalized ads that align with the interests and context of the video content.
Twelve Labs’ Video Classification API
Historically, video classification was constrained to a predetermined set of classes, primarily targeting the recognition of events, actions, objects, and similar attributes. However, the Twelve Labs Video Understanding platform now allows you to customize classification criteria without the need to retrain the model, eliminating the complexities associated with model training.
The platform uses a hierarchical structure to classify your videos:
- Groups of classes form the top level of the structure, and each group comprises multiple classes.
- Classes serve as the primary units of organization, meaning that your videos are categorized into classes.
- Each class contains multiple prompts that define its characteristics. The prompts act as building blocks for the classification system, enabling a precise placement of videos into relevant classes based on their content.
For more information about our Classification capability, check out this tutorial and this page on using Classification programmatically.
2.4 - Video Clustering
Video clustering is the task of grouping videos based on their content similarity without using any labeled data. It involves extracting video embeddings, which capture the visual and temporal information in the videos. These embeddings are then used to measure the similarity between videos and group them into clusters.

You can see a parallel with text clustering, where documents are represented as high-dimensional vectors, usually based on the frequency of words or phrases in the text. In both tasks, the goal is to group similar content, making it easier to analyze, categorize, and understand the data.
Challenges
Performing video clustering poses several technical challenges. Videos are high-dimensional data with multiple frames, making the clustering process computationally expensive. The large number of features extracted from each frame increases the complexity of the clustering algorithms.
Furthermore, determining the appropriate clustering criteria and similarity measures for video data can be subjective. Different clustering algorithms and parameter settings may yield different results, requiring careful selection and evaluation to achieve meaningful clusters.
Use Cases
Video clustering can help improve various applications, such as video topic modeling and automatic video categorization.
- In video topic modeling, you can cluster videos with similar topics, allowing for more effective video content analysis and identification of trends and patterns. This can be particularly useful in applications such as social media analysis, where large volumes of video data need to be analyzed quickly and accurately.
- In automatic video categorization, you can cluster videos into categories based on their content similarity without the need for manual labeling. This can be useful in various applications such as video content-based retrieval databases, online video indexing and filtering, and video archiving. (Note: Video-to-Video Search is a feature on the Twelve Labs product roadmap, which allows you to automatically categorize your videos. Contact us at support@twelvelabs.io for more info)
- In video content recommendation, video clustering enables the creation of personalized video recommendations. In a vector space, video embeddings can be combined with other types of data, such as user metadata and viewing history, to generate highly personalized recommendations. This approach helps users discover relevant and engaging videos that align with their interests and preferences.
3 - Video-Language Modeling
3.1 - The Rise of Multimodal LLMs
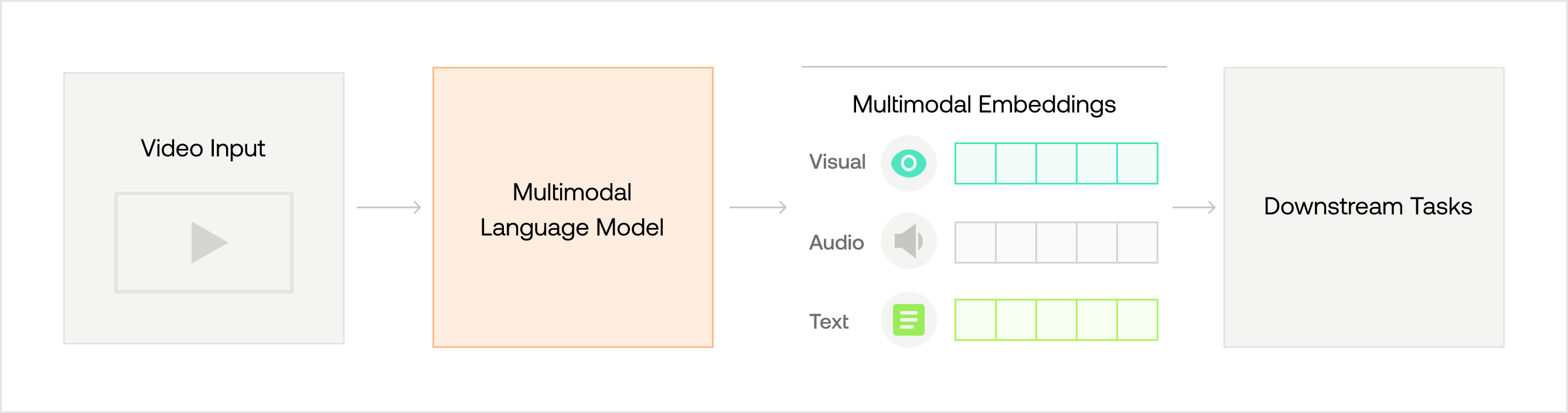
The rise of multimodal large language model (LLM) research has been driven by the need to process and understand various types of data, such as text, images, audio, and video, simultaneously. Traditional LLMs, which are trained on textual data, have limitations in handling multimodal tasks. Multimodal LLMs, on the other hand, can process all types of data using the same mechanism, leading to more accurate and contextual outputs. This has opened up new possibilities for AI applications, as these models can generate responses that incorporate information from multiple modalities.
Video-language modeling is a specific application of multimodal LLMs that focuses on understanding and generating text-based summaries, descriptions, or responses to video content. This line of research is essential for holistic video understanding, as it aims to bridge the gap between visual and textual understanding. This integration of text and video data in a common embedding space allows the models to generate more contextually relevant and informative outputs, benefiting various downstream tasks.
For example, models such as VideoBERT and LaViLa can be used to automatically generate descriptions for videos, improving accessibility and search-ability. They can also be applied to video summarization, where the models generate concise textual summaries of video content. Additionally, a model like Video-ChatGPT can enhance interactive media experiences by generating human-like conversations about videos.
3.2 - Video Description and Summarization

Video description is the task of producing a complete description or story of a video, expressed in natural language. It involves analyzing multiple elements of a video and generating a textual description that accurately captures the content and context of the video. On the other hand, video summarization is the task of generating concise textual summaries based on the content of videos (while preserving the essential information and key moments). It condenses long videos into concise representations that capture the most important content and then provides textual descriptions matching such representations.
Both video description and summarization can improve comprehension and engagement of videos. They can help viewers better understand the content of a video, especially if they have visual impairments or other disabilities that make it difficult to see or hear the video. Additionally, they can help keep viewers engaged with a video by providing additional context and information that they might not have otherwise noticed.

Challenges
Videos can contain diverse scenes, actions, and events, making it challenging to generate accurate and comprehensive descriptions and summaries. Therefore, the model must capture the complex relationships between visual and textual information in videos.
In addition, video description and summarization requires accurately aligning the generated descriptions and summaries with the corresponding video segments. Achieving precise temporal alignment is a challenge, particularly when dealing with fast-paced or complex video content. Models that incorporate attention mechanisms and leverage multimodal information have been shown to have more accurate temporal alignment.
Finally, the generated descriptions and summaries must not only be accurate but also coherent and contextually relevant to the video content. Therefore, the model needs to effectively capture the semantics and context of the video while generating fluent and meaningful sentences.
Use Cases
Video description and summarization have various applications in different industries. Here are some examples:
- In the media and entertainment industry, they can be used to create previews or trailers for movies, TV shows, and other video content. These previews provide a concise overview of the content and help viewers decide whether to watch the full video.
- In the e-commerce industry, they can enhance the shopping experience by providing concise summaries or highlights of product videos. This allows customers to quickly understand the key features and benefits of a product without watching the entire video.
- They have valuable applications in the education and training sector - such as the development of video lectures or tutorials with accompanying textual descriptions that provide an overview of the content. This helps students navigate through the video and quickly find the sections that are most relevant to their learning objectives.
- They can be utilized in marketing and advertising campaigns to create engaging and informative video content. By providing concise descriptions or summaries, marketers can capture the attention of viewers and deliver key messages effectively.
- They are valuable for social media platforms and content sharing websites. By automatically generating captions or descriptions for user-uploaded videos, they can be used to create auto-generated previews or highlights for shared videos, increasing engagement and user interaction.
3.4 - Video Question Answering

Video question answering (QA) is the task of answering questions related to videos through semantic reasoning between visual and linguistic (and perhaps audible) information. The goal is to provide answers to specific questions about the content of a video. This can help make a video more accessible to a wider audience (including those who speak different languages) and provide interactive elements that allow users to interact with the content.
Challenges
Video QA is a task that involves answering complex questions in natural language, which requires a deep understanding of the video content. This means that the model must effectively capture the semantics and context of the video while generating fluent and meaningful answers.
To generate accurate answers, video QA requires the integration of multiple modalities, such as visual, audio, and textual information. In other words, the model needs to possess multimodal understanding.
Finally, video QA requires the ability to reason about the temporal relationships between different events and actions in the video. Therefore, the model needs to be able to effectively capture the temporal dynamics of the video and reason about the relationships between different events and actions.
Use Cases
Video question answering has various applications in different industries:
- Customer Support: Video QA can be used to provide customer support through video chat or messaging. Customers can ask questions about a product or service, and the system can generate a textual or spoken response based on the content of a video.
- Educational Content: Video QA can be used to create interactive educational content. Students can ask questions about a video lecture, and the system can generate a textual or spoken response based on the content of the video.
- Interactive Media: Video QA can be used to create interactive media experiences, such as games or virtual reality environments. Users can ask questions about the content of a video, and the system can generate a response that affects the outcome of the experience.
Twelve Labs is working on a new Generate API that can generate concise textual representations such as titles, summaries, chapters, and highlights for your videos. Unlike conventional models limited to unimodal interpretations, the Generate API suite uses a multimodal LLM that analyzes the whole context of a video, including visuals, sounds, spoken words, and texts and their relationship with one another. Stay tuned for the exciting release!
4 - Conclusion
Video understanding has become an essential field of research in the era of multimedia content. With the rapid growth of video data, it has become increasingly important to develop models and techniques that can make sense of the vast amount of information contained within videos. As we have seen, video understanding has numerous use cases, including video search, video classification, video clustering, video description and summarization, and video question answering. These applications have the potential to revolutionize various industries, from entertainment to education to customer support.
The development of video foundation models and video-language models has paved the way for significant advancements in video understanding. As the field continues to evolve, we can expect to see further innovations in both the models themselves and the applications they enable. By developing models that can holistically understand video content, we can make video data more accessible, searchable, and useful.
At Twelve Labs, we are developing foundation models for multimodal video understanding. Our goal is to help developers build programs that can see, listen, and understand the world as we do with the most advanced video-understanding infrastructure. If you would like to learn more, please sign up at https://playground.twelvelabs.io/ and join our Multimodal Minds Discord community to chat about all things Multimodal AI!
Generation Examples
Comparison against existing models
Related articles

A beginner guide to video understanding for M&E with MASV and Twelve Labs


"Generate titles and hashtags" app can whip up a snazzy topic, a catchy title, and some trending hashtags for any video you fancy.


Our video-language foundation model, Pegasus-1. gets an upgrade!


This blog post introduces Marengo-2.6, a new state-of-the-art multimodal embedding model capable of performing any-to-any search tasks.
